Takeaways from DeepMind's RoboCat Paper
Visual Foundation Models still need robot data to work well on robots. News at 11.
DeepMind Robotics published the paper "RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation (PDF)" earlier this week. I read the 50-page report and summarize in this post what I found to be the most interesting results from the paper. Some of my claims and inferences in this blog post are speculative because they draw from my experience working on similar projects (BC-Z, SayCan, MGDT).
For a broad-audience overview of what RoboCat is, please check out DeepMind's blog post. If any Google DeepMinders want to point out any factual inaccuracies, please contact me via Twitter or Email.
Overview
The overarching research question many academic robotics labs are focused on today is "how do we get one big Transformer model to do all the robotic tasks, much the same way that Transformers can do all the language tasks and do all the vision tasks?" The tried-and-true recipe of the last few years is that if you can cast your prediction problem into discrete input tokens and output tokens, then you can basically outsource the machine learning to a NLP architecture (e.g. a vanilla Transformer). NLP is the domain that is at the forefront of generalization as humans understand it, so it's no surprise that the models that generalize for multi-lingual NLP also generalize for anything else that can be cast into tokens. All the models are consolidating to Transformers, so it's about time for robotics to do the same.
At its core, machine learning is about generalization and transfer, and this is what the RoboCat paper focuses on studying. Generalization typically refers to how much training on domain A benefits testing on domain B, especially when B might differ from A in some way. Transfer typically refers to how much training on domain A benefits fine-tuning on domain B, especially when B might differ from A in some way. Transfer learning is also what you focus on in your paper when your zero-shot generalization results aren't super strong yet 🙈. Of course, the boundaries between transfer and generalization are blurry when it comes to things like in-context adaptation.
Based on the author list and infrastructure, RoboCat can be thought of as the sequel to the GATO paper. I've previously tweeted some thoughts about GATO here. I'm guessing RoboCat authors decided to focus on cross-robot transfer because it was very unclear whether the vision and Atari tasks in GATO actually helped learn the robotics tasks, so they wanted to redo the study of generalist robot agents in a more controlled manner.
Engineering lesson: When doing research on transfer learning, if you are not seeing positive transfer between tasks, you should try to pre-training on something closer to your test set first.
From a model architecture standpoint, RoboCat is very similar to RT-1: learn a tokenizer for robotics images, tokenize your proprioception and future actions in the simplest way possible, then predict future action tokens with a Transformer. While the RT-1 paper emphasizes LLM-enabled unseen instruction generalization and the visual complexity afforded by long-horizon mobile manipulation, RoboCat focuses on relatively harder manipulation tasks (e.g. NIST-i gears, inverted pyramid, tower building) and comparing transfer learning performance on their RoboCat foundation models vs. Internet-scale foundation models. In a big picture sense, both these projects are headed in the same direction and I would not be surprised if they are soon consolidated under the new Google + DeepMind re-org.
In terms of scientific contributions, the RoboCat paper contains a trove of empirical data on how to unify multiple robot embodiments in a single model, how much cross-task transfer to expect, how well learning recipes work when transferred from sim to real, the magnitude of data required, architecture and parameter scaling experiments, comparing between tokenization strategies for perception, and how to set up reset-free automated evaluation in the real world for multi-task policies. This project was put together by a team of 39 authors working over the course of a year to build infra, collect data, train, evaluate, run baselines, and compile the technical report. This was a titanic amount of work, and kudos to the team for doing this.
What I find most impressive is that they evaluate these questions on (1) 253 tasks across sim and real (2) they got many tasks working for multiple robots (sim Sawyer, sim Panda, real Sawyer, real Panda, real KUKA). Everyone who works on real-world robots knows that automating a single task on a single robot in the real world is difficult enough as it is. Cross-robot transfer is one of the most obvious ideas ever, but people rarely try it because it is such a world of pain to set up. It's pretty clear from this paper that the DM team went to great lengths to detail the training data set and evaluation protocols and show consistent results on all the robots and action spaces. My team at 1X is working on our own "big model to do all the tasks", so the tables and graphs in this paper de-risk a lot of the questions we're tackling now.
On Action Spaces
Choice of action space has a huge impact on the performance of a robotic system. My rule of thumb is that task difficulty, measured in samples needed to learn the task, is roughly exponential in the length of the episode and exponential in the independent dimensions of the action space. According to Table 10, the episode durations are 20-120 seconds, about 2-4x longer than typical tasks in BC-Z and SayCan. However, the low success rates of the human teleoperators on these tasks (e.g. 50% on tower building) suggest that better autonomous performance can be obtained if one put in the engineering effort to improve the ease of teleoperating these tasks. I think if they could shorten tower building from 60 to 30 second demonstrations, the resulting improvement in task success will eclipse pretty much any algorithmic idea you can come up with.
RoboCat predicts cartesian 4 or 6 DoF cartesian velocities for the arm, and 1 DoF (parallel jaw gripper) or 8 DoF (3-finger) for the hand. This results in a single neural network that can handle 5, 7, or 14-DoF action spaces, and a variable proprioception sizes. Sequence modeling essentially gives you a simple yet universal interface for mixing observation and action spaces. GATO and RT-1 did it first, but RoboCat shows that not only is it possible to merge multiple robot embodiments with a unified interface, you can get some positive transfer when you train these together. If one robot has a 4-DoF manipulator, the model predicts 4 tokens. If another arm has a 6-DoF end effector (e.g. xyz translation and rpy rotation), the model switches to predicting 6 tokens. If you have a dataset with hundreds of robot morphologies, this is the right way to scale instead of having one prediction head for every embodiment, HydraNet style. We are starting to see this "just map all outputs to a non-fixed length sequence" trend in perception, so I expect eventually everyone just converges to training VQA models.
Predicting cartesian velocities from axis-aligned images probably helps with learning visual servoing, though with the scale of data collected, I'm pretty sure they could have generalized their tokenization to other action spaces (e.g. other coordinate frames, joint angles, etc).
Will Visual Foundation Models Zero-Shot Robotics?
The 2022 Flamingo paper gave some preliminary evidence that at some sufficiently large scale, foundation models trained on Internet-scale data might outperform fine-tuning on in-domain data. The question weighing on many researcher's minds these days is whether visual foundation models (sometimes referred to as VLMs) like GPT4 + Images will just zero-shot robotics. If the answer is yes, then roboticists should stop wasting their time on real robots and their difficulties and just work on computer vision and NLP benchmarks like everyone else until the model wakes up one day and knows how to control motors.
RoboCat authors study this question by fine-tuning 59 VFMs pretrained on Internet-scale data on each task. Thank goodness for labs that have the resources to do this. They selected the best two models for sim real world evaluation: CLIP-pretrained NFNet-f6 and CLIP-pretrained Swin-L.
These models have reasonably OK performance in sim but are pretty terrible in real compared to training their RoboCat Transformer from scratch. This does suggest that real-world collected data will remain quite valuable for the forseeable future. Perhaps the action and proprioception token distributions do need to be quite diverse for the pretraining objective to work.
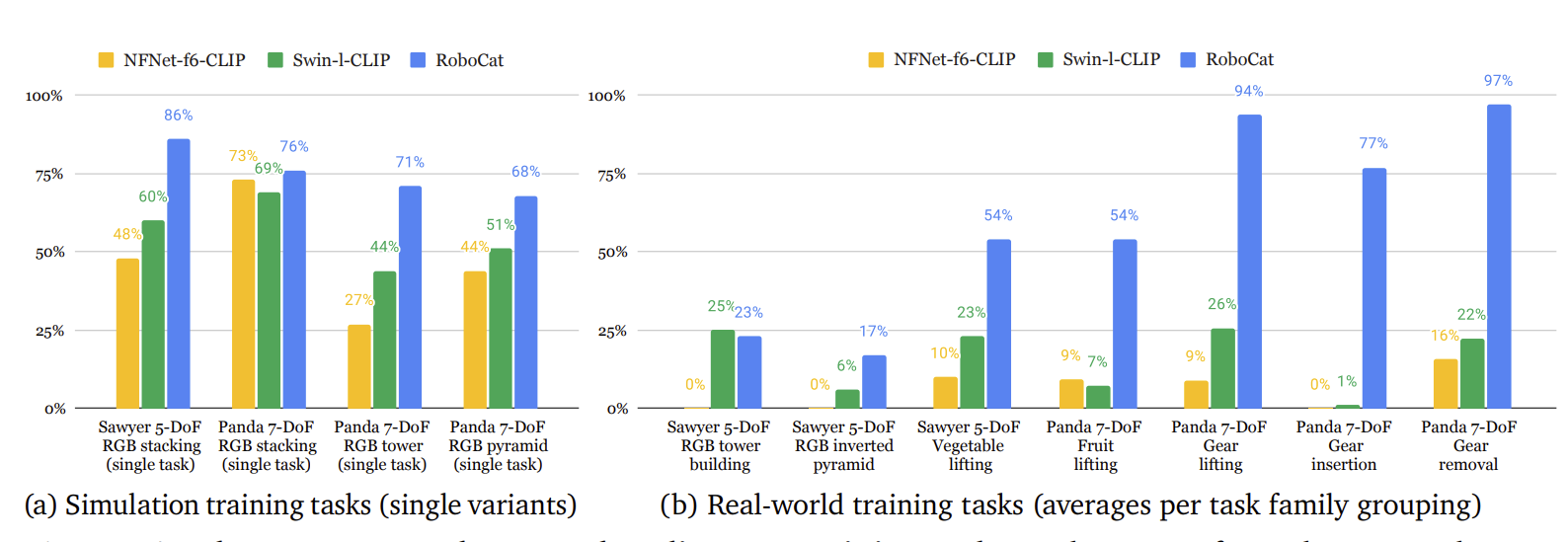
Some additional remarks:
-
The extensive VFM sweep makes me wonder if the project began as an effort to get one of these foundation models to work out of the box, and then the team ended up having to train their own model as a result of the baselines not working in real, perhaps merging efforts with a larger DM project that had set up the real world data collection infra.
-
It would have been really nice to see how FAIR's VC-1 foundation model performed on these tasks. Alas, VC-1 has an annoying CC-by-NC license that will cause its impact to not live up to its potential. Maybe DeepMind could try fine-tuning Segment-Anything instead, or FAIR can do us all a solid and fix the license.
-
There are some results I don't know how to explain. Swin-l outperforms NFNet-f6 by a lot in fine-tuning on 500-1000 images for sim and real (Fig 5, Fig 6) but the trend is reversed in the few-shot context. In Table 17 of the appendix, I can see no discernable pattern of how dataset, training objective, or model architecture affect the transfer performance. To palagarize Tolstoy, "all good models are the same, all crappy baselines are bad in their own unique way". Visual representation learning as a field is a bit sketchy because it's hard to compare representation learning algorithms (e.g. DINO, MAE) without some kind of concrete downstream task. Well, the downstream tasks have spoken and … it's not clear if any of the representation learning algorithms are differentiated enough to make a difference for robotics. The data distributions that we learn visual representations on still matter more than the loss function, architecture, model size, etc.
-
I'm surprised that they did not report the baseline of training the single-task baselines on 1000 demonstrations from a randomly initialized network instead of a pre-trained model. 1000 demos is a non-trivial amount of demonstrations, and I could easily imagine the success rates being comparable to the worst VFMs in Table 17.
Small Difference in Train, Big Difference in Test
This paper identifies three ablations that hurt performance on held-out tasks while having a less deleterious effect on that of training tasks.
- Fine-tuning on RoboCat vs. VFM baselines (Figure 6)
- VQ-GAN tokeniser vs. Patch ResNet tokenizer (Figure 18).
- Predicting future image tokens instead of future image pixels (Figure 19)
These findings make a lot of sense; if you want to maximize your model's ability to fine-tune on any future data, you want to preserve as much information as possible in the features without throwing them away to solve your training tasks. Fine-tuning a proprioception and action-aware VFM, learning a VQ-GAN codebook, and autoregressively compressing future image tokens are all pointed in the direction of lossless generative modeling.
Lesson: if you want transfer learning to work, use features that don't throw away information from your pre-training corpus. This increases the chances that there is something in the pretrained model that can help solve the test task at hand.
I thought the choice of using a VQ-GAN for tokenization was clever, because you can use it to decode the model's future predicted tokens and visualize what the model thinks will happen in the future. Checking if these future images are reasonably on-task is a good way to quickly visualize the model for correctness, and saves a lot of time evaluating the policy in sim or real.

Interestingly, this requires training the VQ-GAN on ImageNet + Mujoco + MetaWorld images to attain good generalization but I'm not sure why. Maybe it's the same "compress everything so that you have some useful features for anything the test set throws at you" argument, except applied to the tokenizer "perception" layer.
The Mystery of the Moving NIST-i Board
Appendix G.3 has a fun little "side quest" of that attempts to explain the following observation: The real-world success rate of a 400M agent trained on RoboCat-lim jumps from 38% to 64% when the NIST-i board is fixed to the center of the workspace, despite not having been trained on fixed-base data in real. Why is this the case?
-
One hypothesis is that the board position is fixed in sim, so maybe the agent has overfit to this scenario in sim and carried it over to real.
-
An alternate hypothesis is that the real data distribution is actually biased towards the center - perhaps the teleoperators preferentially gathered demonstrations where the board was centered close to where it is fixed. To test this, they train single-task BC agents on the insertion task, and find that these policies have fairly constant success rate between fixed and moving board base. The assumption is that if there was indeed a dataset bias and not skill transfer, BC agents would do much better with centered base positions, but this isn't the case.
-
Increasing the model size from 400M to 1.2B and pooling the insertion data with the rest of the RoboCat tasks reduces the performance gap between fixed and moving base. This is consistent with the skill transfer hypothesis, since bigger models tend to be better at skill transfer.
It would be much more conclusive if they were able to demonstrate the converse: collect gear insertion with a moving base in sim, and see if training on it results in a success rate that is comparable or higher than 64% (the sim-to-real positive transfer amount for a fixed base in sim).
Summary
Overall, this is a solid paper that makes a lot of good modeling and data engineering choices that are amenable to scaling up robotics. While none of the ideas are really new, sometimes a lack of empirical surprise paired with a lot of rigor is what the community needs.
In 2023, robotics research, mine included, continues to be largely unreproducible. It is the elephant in the room of the robotic learning community. If this RoboCat project were independently replicated in a different lab, with a change as mundane as a differently sized bin, I suspect the experimental results would turn out different. If the project were re-started on a different set of manipulation tasks and robot hardware, the results are almost guaranteed to be different. The systems involve so much complex engineering that asking two different grad students to implement the same thing will probably yield different results too. The choice of whether you bolt the board to the table or not probably has a larger effect size on performance than any of your baseline ablations, and hundreds of these choices are implicitly baked into the data distributions without the researcher being aware of it.
It calls into question whether our real-world robotic tasks are still good enough to discern meaningful conclusions about the relative capability of learning algorithms. My team at 1X is relentlessly focused on solving evaluation for general-purpose robots, so that we can reproduce these experiments with even more rigor and a thousand times the number of tasks. If this kind of work excites you, please feel free to reach out. Until then, just stick with a Transformer and tokens - it'll probably just work.