Science and Engineering for Learned Robots
Why I believe end-to-end Machine Learning is the right approach for solving robotics problems, and invite the audience to think about a couple interesting open problems that I don't know how to solve yet.
I'm a research scientist at Robotics at Google. This is my first full-time job out of school, but I actually started my research career doing high school science fairs. I volunteered at UCSF doing wet lab experiments with telomeres, and it was a lot of pipetting and only a fraction of the time was spent thinking about hypotheses and analyzing results. I wanted to become a deep sea marine biologist when I was younger, but after pipetting several 96-well plates and messing them up (sorry Francesca!) I realized that software-defined research was faster to iterate on and freed me up to do more creative, scientific work.
I got interested in brain simulation and machine learning (thanks to Andrew Ng's Coursera Course) in 2012. I did volunteer research at a neuromorphic computing lab at Stanford and did some research at Brown on biological spiking neuron simulation in tadpoles. Neuromorphic hardware is the only plausible path to real-time, large-scale biophysical neuron simulation on a robot, but much like wet-lab research is rather slow to iterate on. It was also a struggle to learn even simple tasks, which made me pivot to artificial neural networks which were starting to work much better at a fraction of the computational cost. In 2015 I watched Sergey Levine's talk on Guided Policy Search and remember thinking to myself, "oh my God, this is what I want to work on".
Here is a visualization of my career so far:

The Deep Learning Revolution
We've seen a lot of progress in Machine Learning in the last decade, especially in end-to-end machine learning, also known as deep learning. Consider a task like audio transcription: classically, we would chop up the audio clip into short segments, detect phonemes, aggregate phonemes into words, words into sentences, and so on. Each of these stages is a separate software module with distinct inputs and outputs, and these modules might involve some degree of machine learning.

The idea of deep learning is to fuse all these stages together into a single learning problem, where there are no distinct stages, just the end-to-end prediction task from raw data. With a lot of data and compute, such end-to-end systems vastly outperform the classical pipelined approach. We've seen similar breakthroughs in vision and natural language processing, to the extent that all state-of-the-art systems for these domains are pretty much deep learning models.
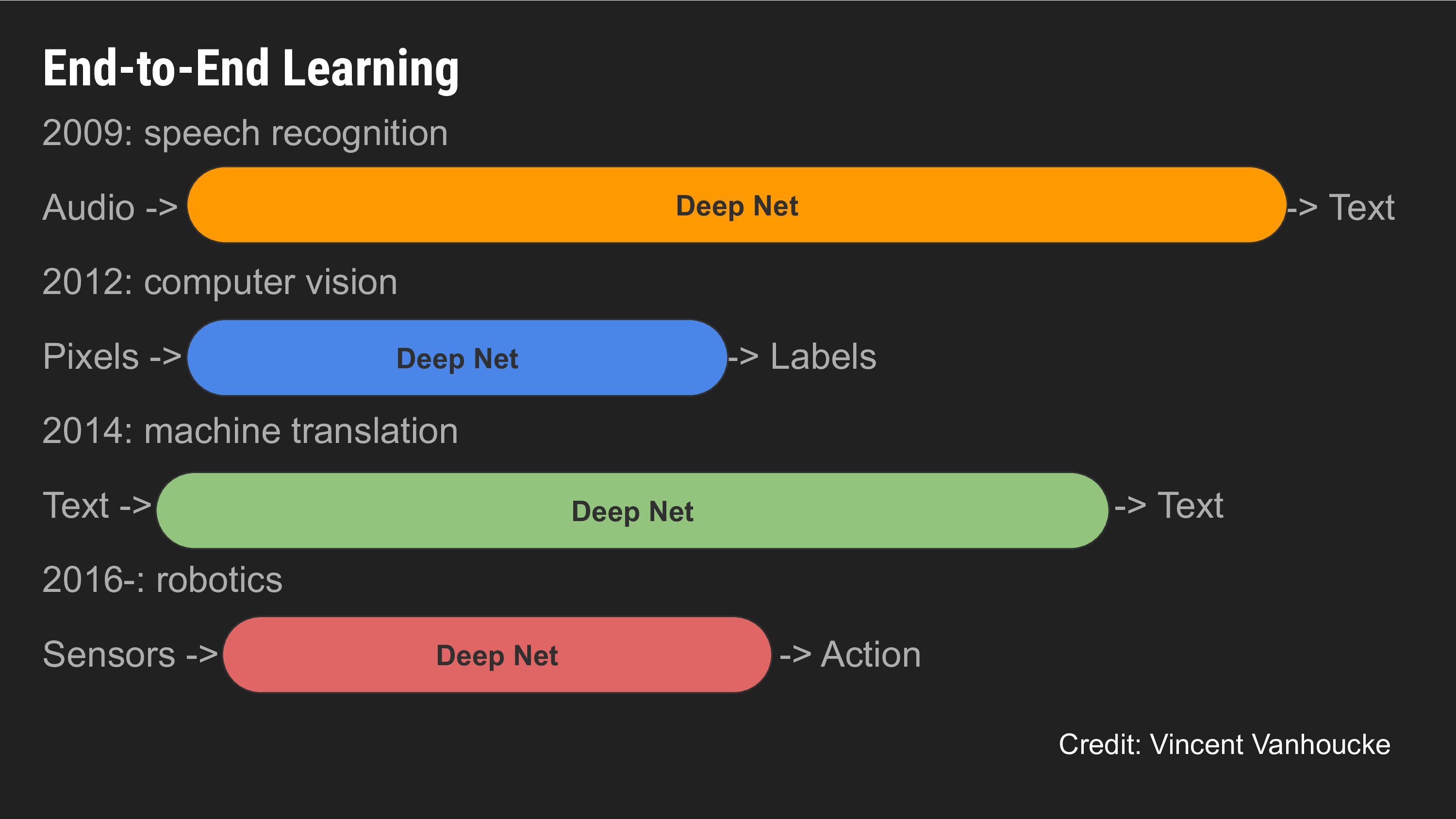
Robotics has for many decades operated under a modularized software pipeline, where first you estimate state, then plan, then perform control to realize your plan. The question our team at Google is interested in studying is whether the end-to-end advances we've seen in other domains holds for robotics as well.
Software 2.0
When it comes to thinking about the tradeoff between hand-coded, pipelined approaches versus end-to-end learning, I like Andrej Karpathy's abstraction of Software 1.0 vs Software 2.0: Software 1.0 is where a human explicitly writes down instructions for some information processing. Such instructions (e.g. in C++) are passed through a compiler that generates the low level instructions of what the computer actually executes. When building Software 2.0, you don't write the program - you give a set of inputs and outputs and it's the ML system's job to finds the best program that satisfies your input-output description. You can think of ML as a "higher order compiler that takes data and gives you programs".
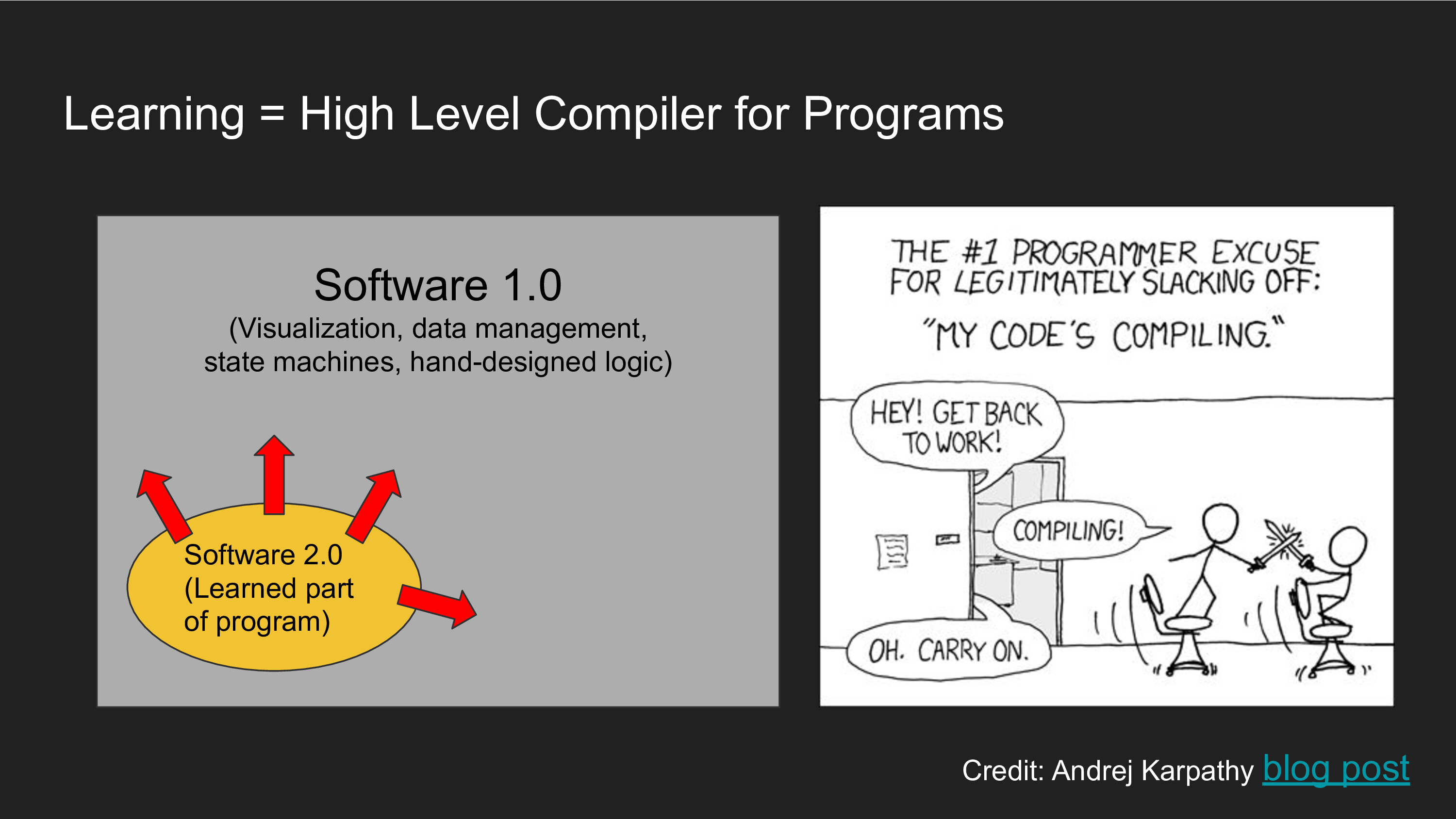
The gradual or not-so-gradual subsumption of software 1.0 code into software 2.0 is inevitable - one might start by tuning some coefficients here and there, then you might optimize over one of several code branches to run, and before you know it, the system actually consists of an implicit search procedure over many possible sub-programs. The hypothesis is that as we increase availability of compute and data, we will be able to automatically do more and more search over programs to find the optimal routine. Of course, there is always a role for Software 1.0 - we need it for things like visualization and data management. All of these ideas are covered in Andrej's talks and blog posts, so I encourage you to check those out.
How Much Should We Learn in Robotics?
End-to-end learning has yet to outperform the classical control-theory approaches in some tasks, so within the robotics community there is still an ideological divide on how much learning should actually be done.
On one hand, you have classical robotics approaches, which breaks down the problem into three stages: perception, planning, and control. Perception is about determining the state of the world, planning is about high level decision making around those states, and control is about applying specific motor outputs so that you achieve what you want. Many of the ideas we explore in deep reinforcement learning today (meta-learning, imitation learning, etc.) have already been studied in classical robotics under different terminology (e.g. system identification). The key difference is that classical robotics deals with smaller state spaces, whereas end-to-end approaches fuse perception, planning, and control into a single function approximation problem. There's also a middle ground where one can attempt to use hand-coded constructs from classical robotics as a prior, and then use data to adapt the system to reality. According to Bayesian decision making theory, the stronger prior you have, the less data (evidence) you need to construct a strong posterior belief.
I happen to fall squarely on the far side of the spectrum - the end-to-end approach. I'll discuss why I believe strongly in these approaches.

Three Reasons for End-to-End Learning
First, it's worked for other domains, so why shouldn't it work for robotics? If there is something about robotics that makes this decidedly not the case, it would be super interesting to understand what makes robotics unique. As an existence proof, our lab and other labs have already built a few real-world systems that are capable of doing manipulation and navigation from end-to-end pixel-to-control. Shown below (right) is our grasping system, Qt-Opt, which essentially performs grasping using only monocular RGB, the current arm pose, and end-to-end function approximation. It can grasp objects it's never seen before. We've also had success on door opening (left) and manipulation from imitation learning (center).

Fused Perception-to-Action in Nature
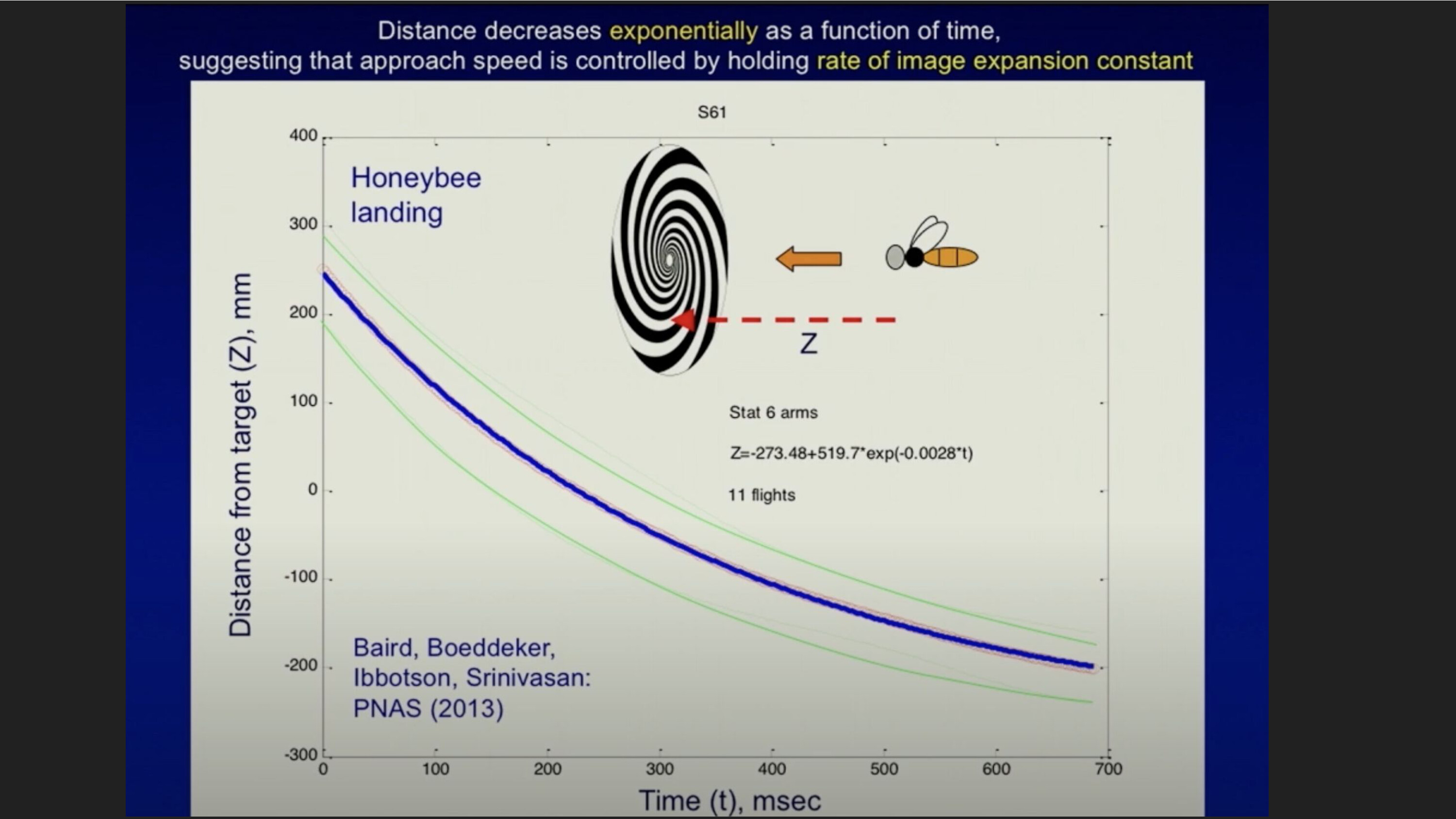
Secondly, there are often many shortcuts one can take to solve specific tasks, without having to build a unified perception-planning-control stack that is general across all tasks. Work from Mandyam Srinivasan's lab has done cool experiments getting honeybees to fly and perch inside small holes, with a spiral pattern painted on the wall. They found that bees will de-accelerate as they approach the target by the simple heuristic of keeping the rate of image expansion (the spiral) constant. They found that if you artificially increase or decrease the rate of expansion by spinning the spiral clockwise or counterclockwise, the honeybee will predictably speed up or slow down. This is Nature's elegant solution to a control problem: visually-guided odometry is computationally cheaper and less error prone than having to detect where the target is in world frame, plan a trajectory, and so on. It may not be a general framework for planning and control, but it is sufficient for accomplishing what honeybees need to do.
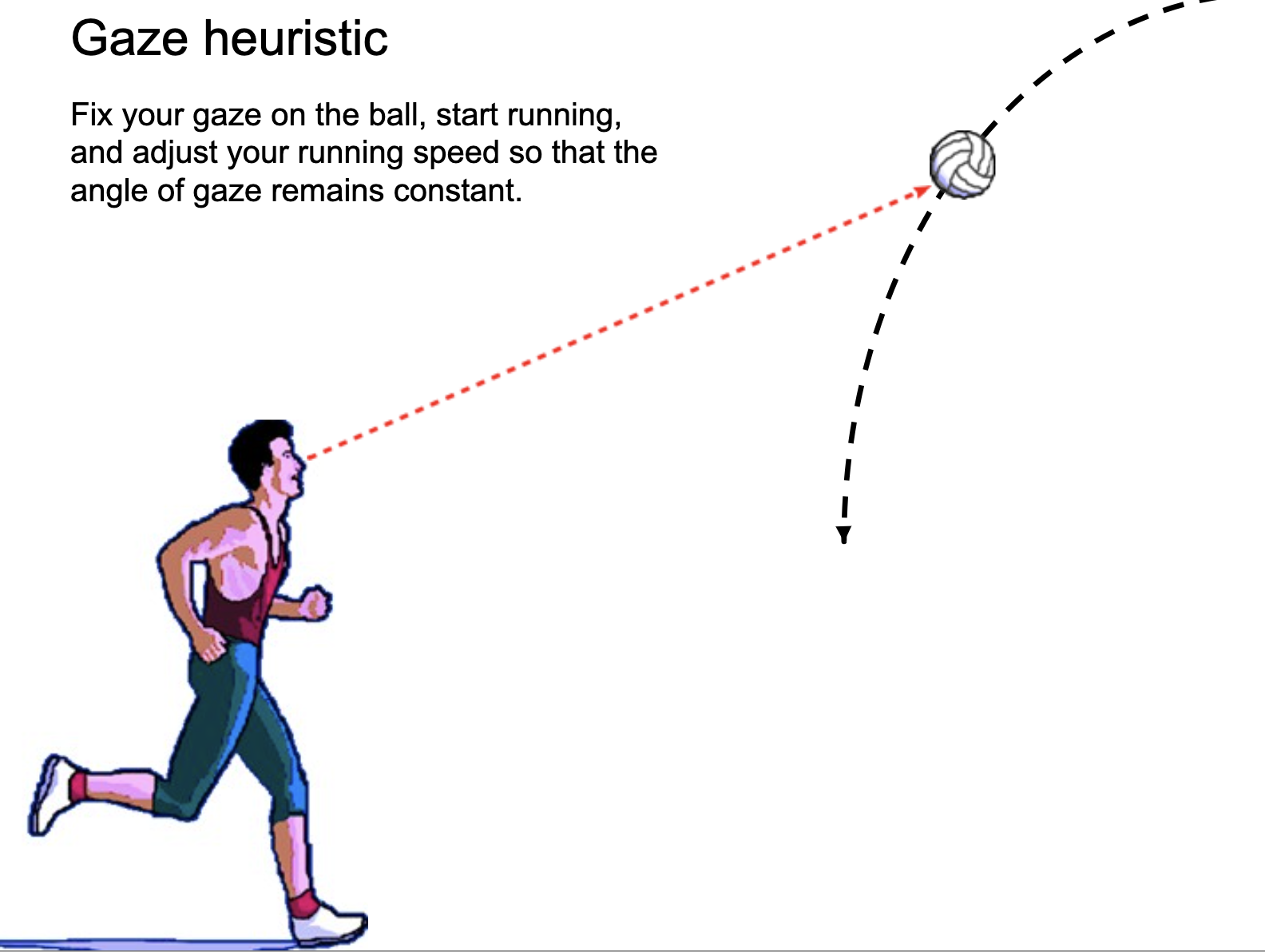
Okay, maybe honeybees can use end-to-end approaches, but what about humans? Do we need a more general perception-planning-control framework for human problems? Maybe, but we also use many shortcuts for decision making. Take ball catching: we don't catch falling objects by solving ODEs or planning, we instead employ a gaze heuristic - as long as an object stays in the same point in your field of view, you will eventually intersect with the object's trajectory. Image taken from Henry Brighton's talk on Robust decision making in uncertain environments.
The Trouble with Defining Anything
Third, we tend to describe decision making processes with words. Words are pretty much all we have to communicate with one another, but they are inconsistent with how we actually make decisions. I like to describe this as an intelligence "iceberg"; the surface of the iceberg is how we think our brain ought to make decisions, but the vast majority of intelligent capability is submerged from view, inaccessible to our consciousness and incompressible into simple language like English. That is why we are capable of performing intelligent feats like perception and dextrous manipulation, but struggle to articulate how we actually perform them in short sentences. If it were easy to articulate in clear unambiguous language, we could just type up those words into a computer program and not have to use machine learning for anything. Words about intelligence are lossy compression, and a lossy representation of a program is not sufficient to implement the full thing.

Consider a simple task of identifying the object in the image on the left (a cow). A human might attempt to string some word-based reasoning together to justify why this is a cow: "you see the context (an open field), you see a nose, you see ears, and black-and-white spots, and maybe the most likely object that has all these parts is a cow".
This is a post-hoc justification, and not actually a full description of how our perception system registers whether something is a cow or not. If you take an actual system capable of recognizing cows with great accuracy (e.g a convnet) and inspect its salient neurons and channels that respond strongly to cows, you will find a strange looking feature map that is hard to put into words. We can't define anything in reality with human-readable words or code with the level of precision needed for interacting with reality, so we must use raw sensory data - grounded in reality - to figure out the decision-making capabilities we want.
Cooking is not Software 1.0
Our obsession with focusing on the top half of the intelligence iceberg biases us towards the Software 1.0 way of programming, where we take a hard problem and attempt to describe it - using words - as the composition of smaller problems. There is also a tendency for programmers to think of general abstractions for their code, via ontologies that organize words with other words. Reality has many ways to defy your armchair view of what cows are and how robotic skills ought to be organized to accomplish tasks in an object-oriented manner.
Cooking is one of the holy grails of robotic tasks, because environments are open-ended and there is a lot of dextrous manipulation involved. Cooking analogies abound in programming tutorials - here is an example of making breakfast with asynchronous programming. It's tempting to think that you can build a cooking robot by simply breaking down the multi-stage cooking task into sub-tasks and individual primitive skills.
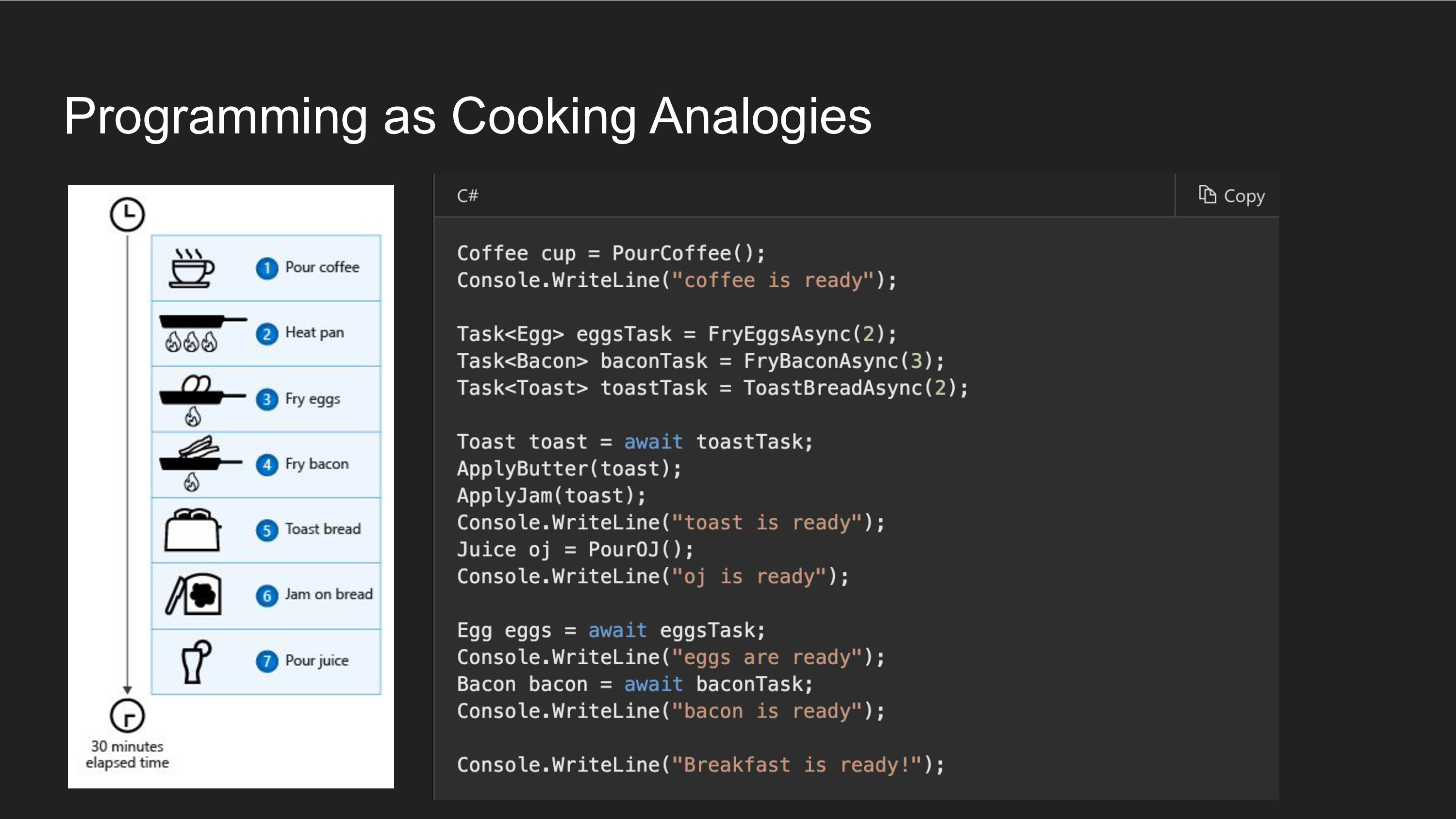
Sadly, even the most trivial of steps abounds with complexity. Consider the simple task of spreading jam on some toast.
The software 1.0 programmer approaches this problem by breaking down the task into smaller, reusable routines. Maybe you think to yourself, first I need a subroutine for holding the slice of toast in place with the robot fingers, then I need a subroutine to spread jam on the toast.
Spreading jam on toast entails three subroutines: a subroutine for scooping the jam with the knife, depositing the lump of jam on the toast, then spreading it evenly.

Here is where the best laid plans go awry. A lot of things can happen in reality at any stage that would prevent you from moving onto the next stage. What if the toaster wasn't plugged in and you're starting with untoasted bread? What if you get the jam on the knife but in the process break something on the robot and you aren't checking to make sure everything is fine before proceeding to the next subroutine? What if there isn't enough jam in the jar? What if you're on the last slice of bread in the loaf and the crust side is facing up?
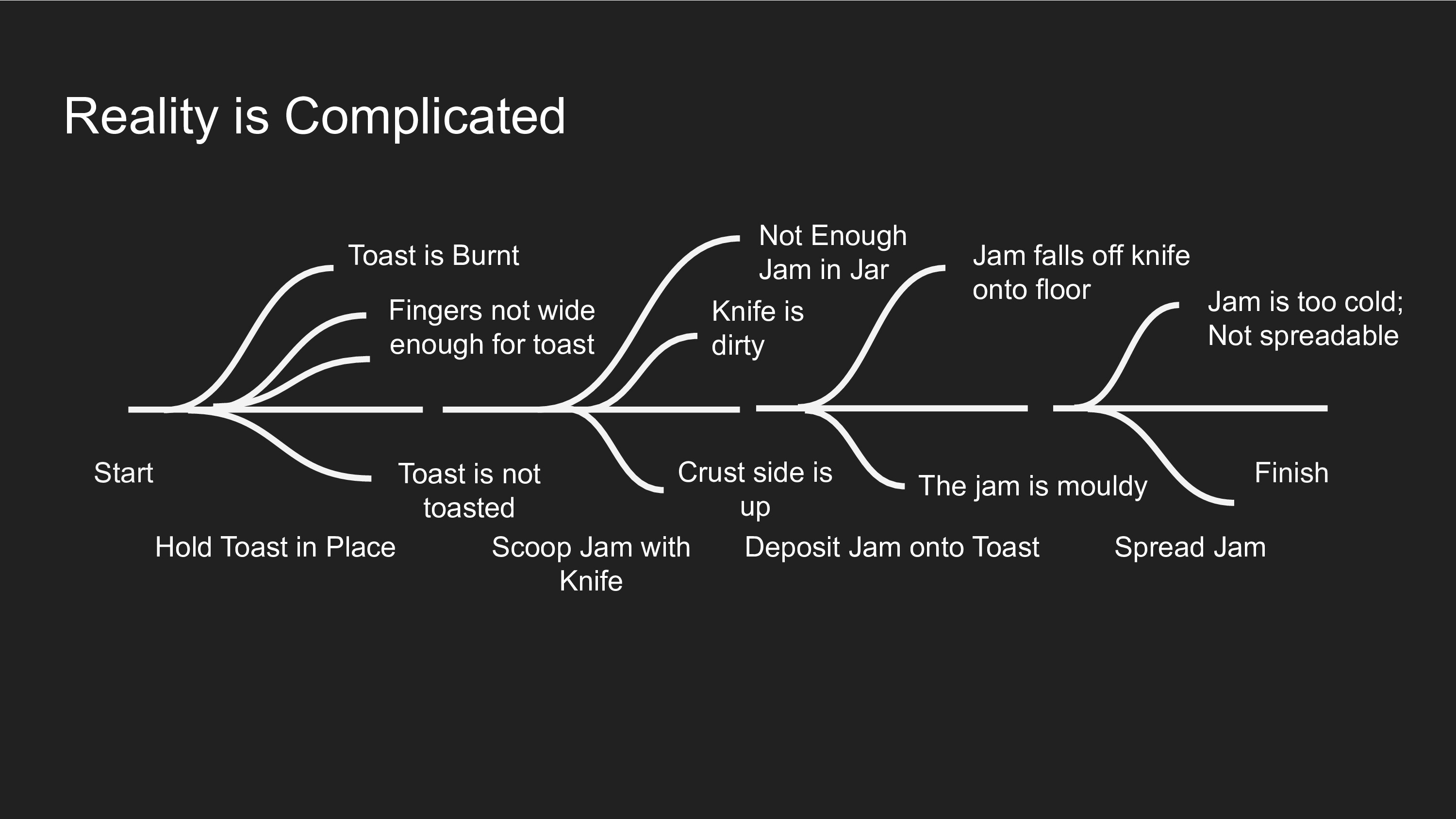
The prospect of writing custom code to handle the ends of the bread loaf (literal edge cases) ought to give one pause as to whether this is approach is scalable to unstructured environments like kitchens - you end up with a million lines of code that essentially capture the state machine of reality. Reality is chaotic - even if you had a perfect perception system, simply managing reality at the planning level quickly becomes intractable. Learning based approaches give us hope of managing this complexity by accumulate all these edge cases in data, and let the end-to-end objective (getting some jam on the toast) and Software 2.0 compiler figure out how to handle all the edge cases. My belief in end-to-end learning is not because I think ML has unbounded capability, but rather that the alternative approach where we capture all of reality into a giant hand-coded state machine is utterly hopeless.
Here is a video where I am washing and cutting strawberries and putting them on some cheesecake.
A roboticist that spends too much time in the lab and not the kitchen might prescribe a program that (1) "holds strawberry", (2) "cut strawberry", (3) "pick-and-place on cheesecake", but if you watch the video frame by frame, there are a lot of other manipulation tasks that happen in the meantime - opening and closing containers with one or two hands, pushing things out of the way, inspecting for quality. To use the Intelligence Iceberg analogy: the recipe and high level steps are the surface ice, but the submerged bulk are all the little micro-skills the hands need to do to open containers and adapt to reality. I believe the most dangerous conceit in robotics is to design elegant programming ontologies on a whiteboard, and ignore the subtleties of reality and what its data tells you.
There are a few links I want to share highlighting the complexity of reality:
-
I enjoyed this recent article on Quanta Magazine about the trickiness of defining life. This is not merely a philosophical question; people at NASA are planning a Mars expedition to collect soil samples and answer whether life ever existed on Mars. This mission requires clarity on the definition of life. Just like it's hard to define intelligent capabilities in precise language, so it is to define life. These two words may as well be one and the same.
-
Klaus Greff's talk on What Are Objects? raises some interesting queestions about the fuzziness of word. Obviously we want our perception systems to recognize objects so that we may manipulate and plan around them. But as the talk points out, defining what is and is not an object can be quite tricky (is a hole an object? Is the frog prince defined by what he once was, or what he looks like now?).
-
I've also written a short story on the trickiness of defining even simple classes like "teacups".
Object (noun): That Which You Can Grasp
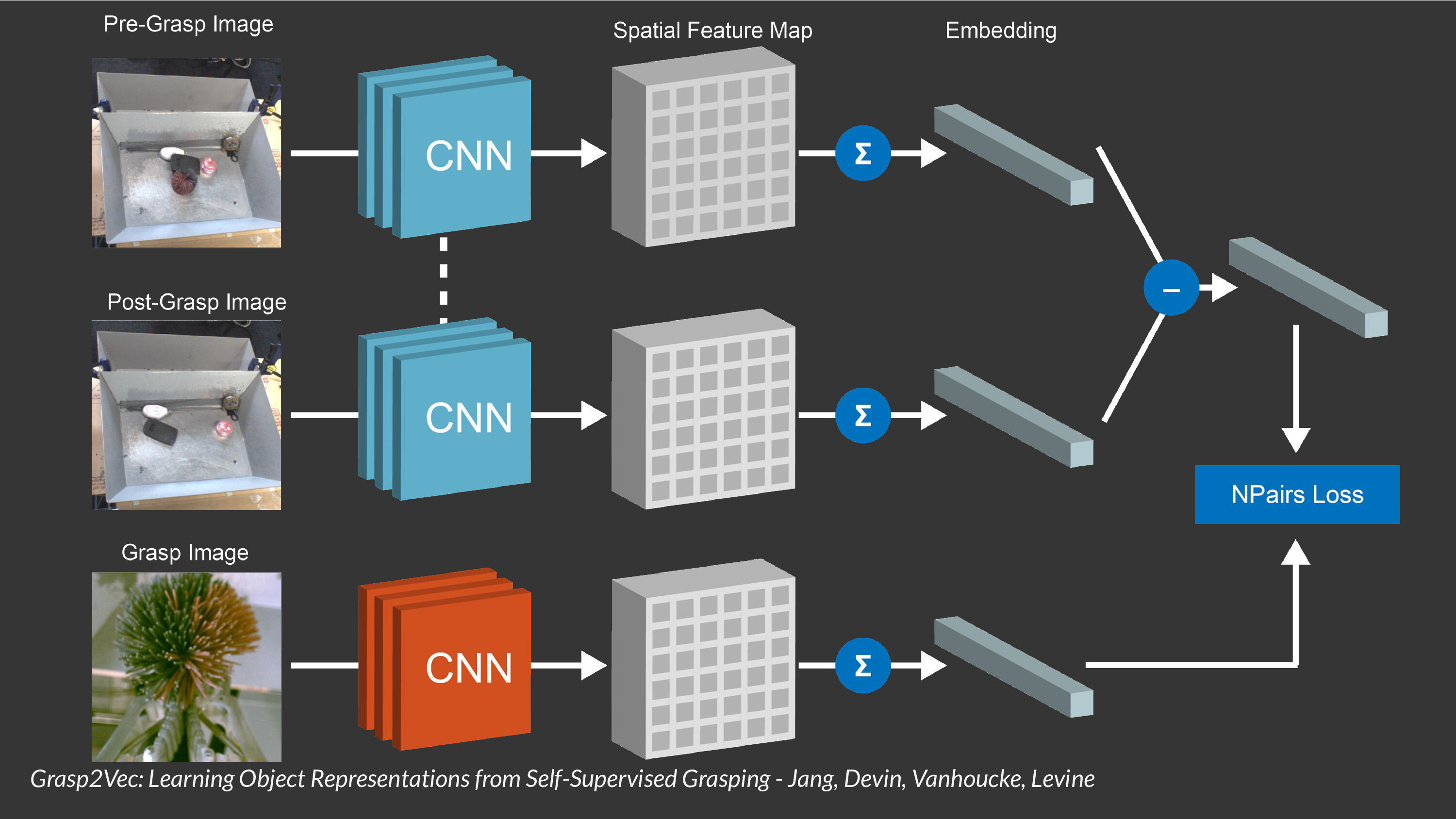
I worked on a project with Coline Devin where we used data and Software 2.0 to learn a definition of objects without any human labels. We use a grasping system to pick up stuff and define objects as "that which is graspable". Suppose you have a bin of objects and pick one of them up. The object is now removed from the bin and maybe the other objects have shifted around the bin a little. You can also easily look at whatever is in your hand. We then design an embedding architecture and use the following assumption about reality to train it: the pre-grasp objects embedding - post-grasp objects embedding to be equal to the embedding of whatever you picked up. This allowed us to bootstrap a completely self-supervised instance grasping system from a grasping system without ever relying on labels. This is by no means a comprehensive definition of "object" (see Klaus's talk) but I think it's a pretty good one.

Science and Engineering of End-to-End ML
End-to-end learning is a wonderful principle for building robotic systems, but it is not without its practical challenges and execution risks. Deep neural nets are opaque black box function approximators, which makes debugging them at scale challenging. This requires discipline in both engineering and science, and often the roboticist needs to make a choice as to whether to solve an engineering problem or a scientific one.
This is what a standard workflow looks like for end-to-end robotics.
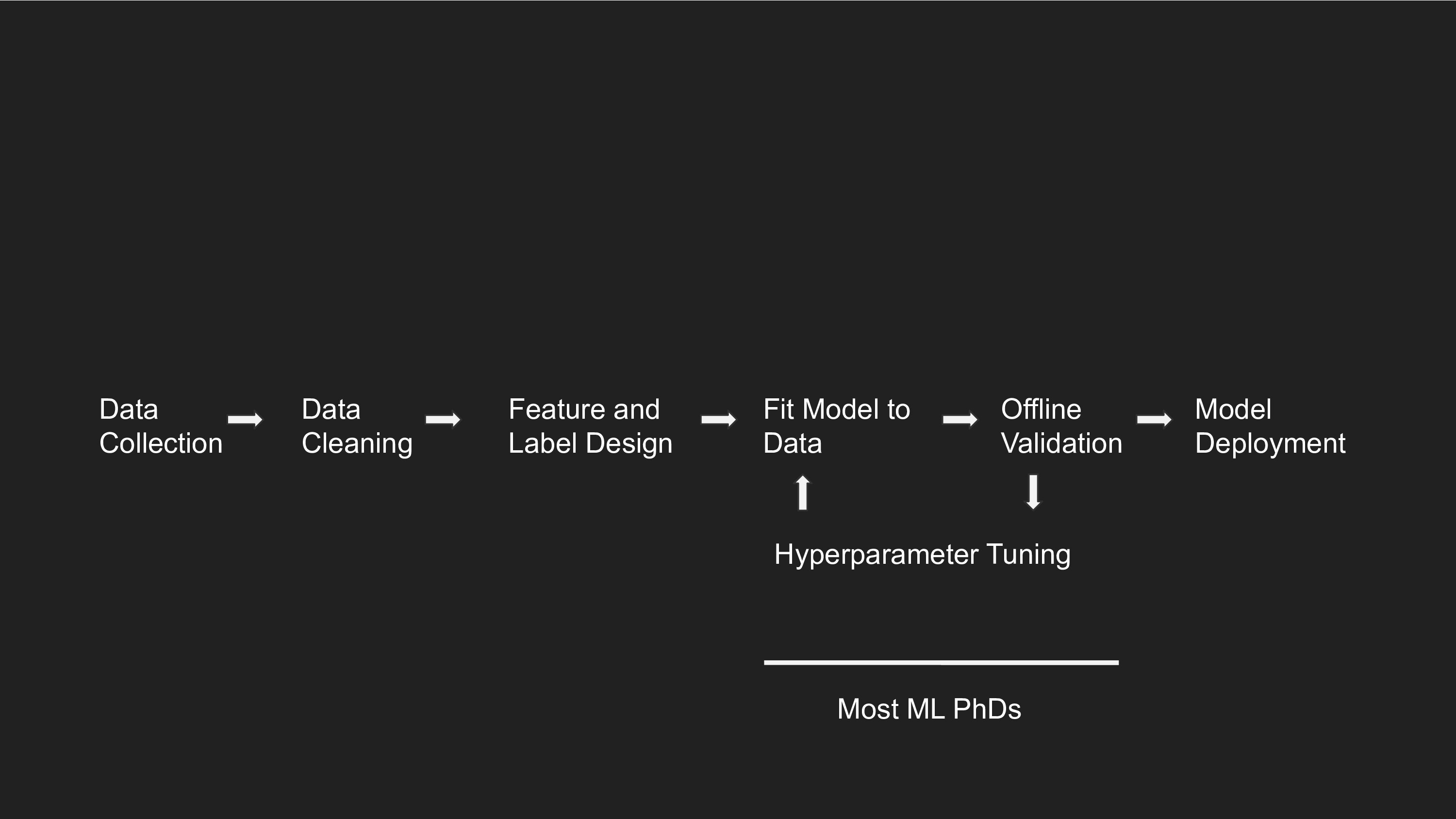
You start by collecting some data, cleaning it, then designing the input and output specification. You fit a model to the data, validate it offline with some metrics like mean-squared error or accuracy, then deploy it in the real world and see if it continues to work as well on your validation sets. You might iterate on the model and validation via some kind of automated hyperparameter tuning.
Most ML PhDs spend all their time on the model training and validation stages of the pipeline. RL PhDs have a slightly different workflow, where they think a bit more about data collection via the exploration problem. But most RL research also happens in simulation, where there is no need to do data cleaning and the feature and label specification is provided to you via the benchmark's design.
While it's true that advancing learning methods is the primary point of ML, I think this behavior is the result of perverse academic incentives.
There is a viscious tendency for papers to put down old ideas and hype up new ones in the pursuit of "technical novelty". The absurdity of all this is that if we ever found that an existing algorithm works super well on harder and harder problems, it would have a hard time getting published on in academic conferences. Reviewers operate under the assumption that our ML algorithms are never good enough.
In contrast, production ML usually emphasizes everything else in the pipeline.
Researchers on Tesla's Autopilot team have found that in general, 10x'ing your data on the same model architecture outperforms any incremental modeling improvement in the last few years. As Ilya Sutskever says, most incremental algorithm improvements are just data in disguise. Researchers at quantitative trading funds do not change models drastically: they spend their time finding novel data sources that add additional predictive signal. By focusing on large-scale problems, you get a sense of where the real bottlenecks are. You should only work on innovating new learning algorithms if you have reason to believe that that is what is holding your system back.
Here are some examples of real problems I've run into in building end-to-end ML systems. When you collect data on a robot, certain aspects of the code get baked into the data. For instance, the tuning of the IK solver or the acceleration limits on the joints. A few months later, the code on the robot controllers might have changed in subtle ways, like maybe the IK solver was swapped with a different solver. This happens a lot in a place like Google where multiple people work on a single codebase. But because assumptions of the v0 solver were baked into the training data, you now have a train-test mismatch and the ML policy no longer works as well.
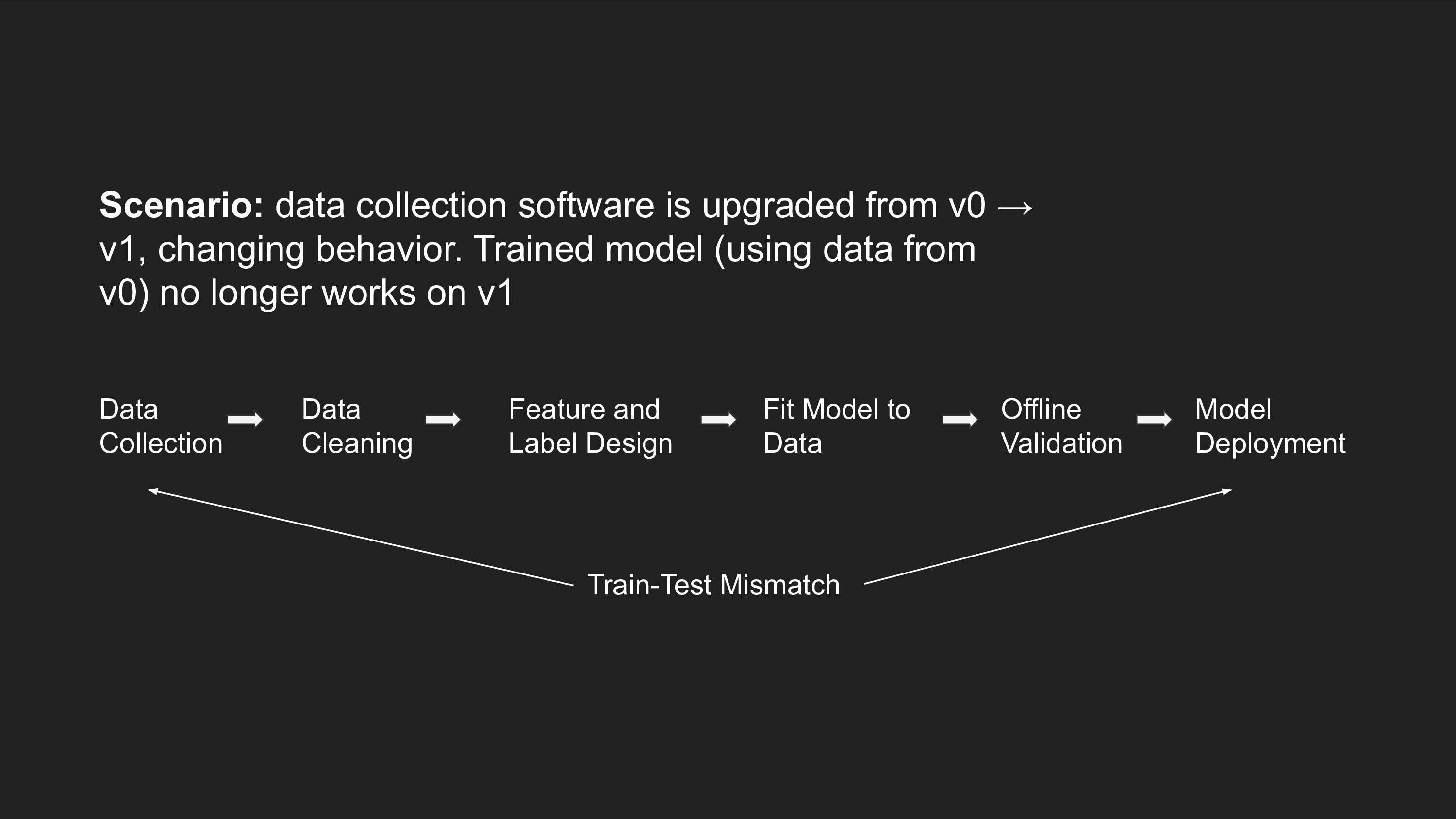
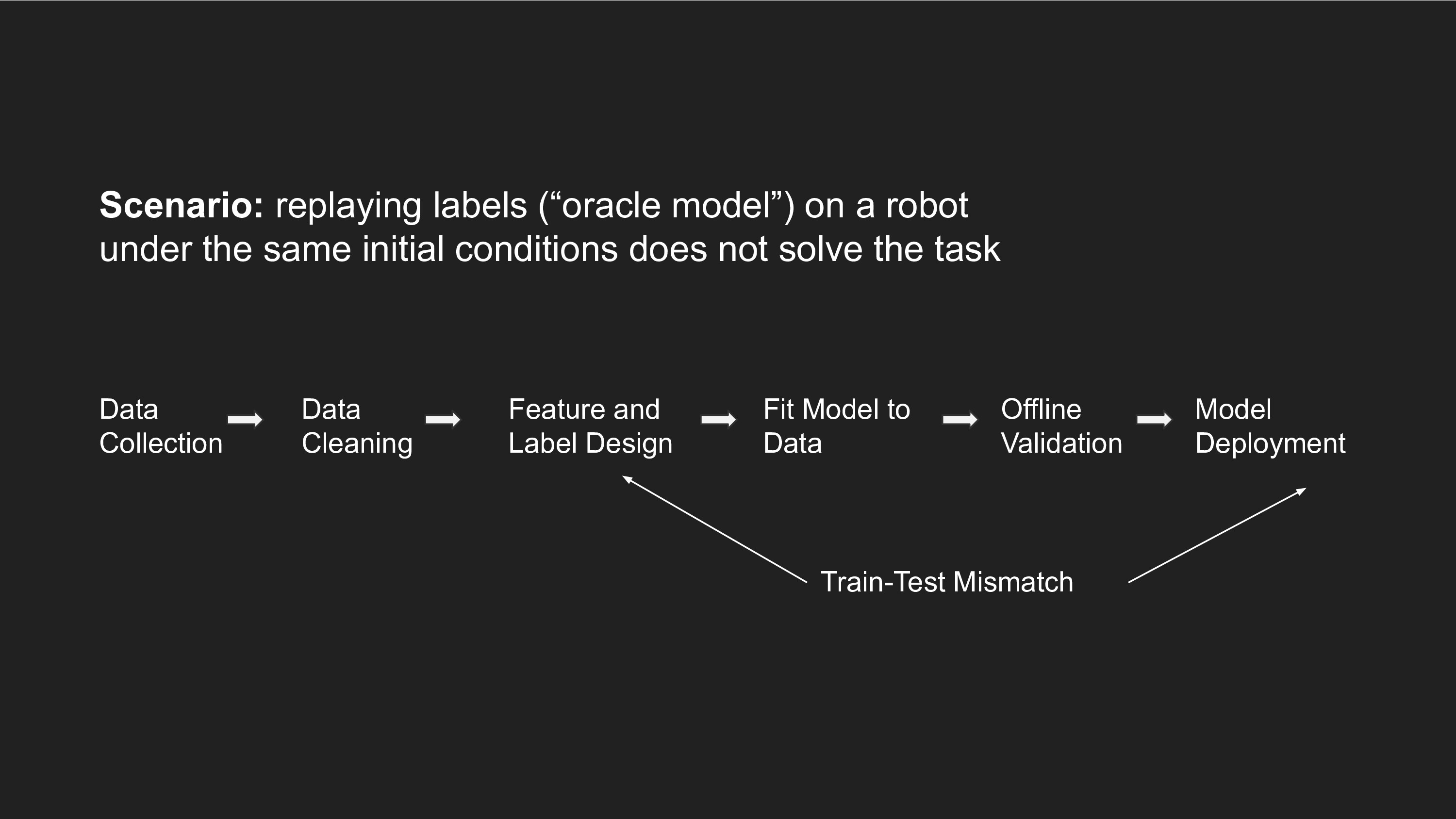
Consider an imitation learning task where you collect some demonstrations, and then predict actions (labels) from states (features). An important unit test to perform before you even start training a model is to check whether a robot that replays the exact labels in order can actually solve the task (for an identical initialization as the training data). This check is important because the way you design your labels might make assumptions that don't necessarily hold at test-time.
I've found data management to be one of the most crucial aspects of debugging real world robotic systems. Recently I found a "data bug" where there was a demonstration of the robot doing nothing for 5 minutes straight - the operator probably left the recording running without realizing it. Even though the learning code was fine, noisy data like this can be catastrophic for learning performance.

As roboticists we all want to see in our lifetime robots doing holy grail tasks like tidying our homes and cooking in the kitchen. Our existing systems, whether you work on Software 1.0 or Software 2.0 approaches, are far away from that goal. Instead of spending our time researching how to re-solve a task a little bit better than an existing approach, we should be using our existing robotic capabilities to collect new data for tasks we can't solve yet.
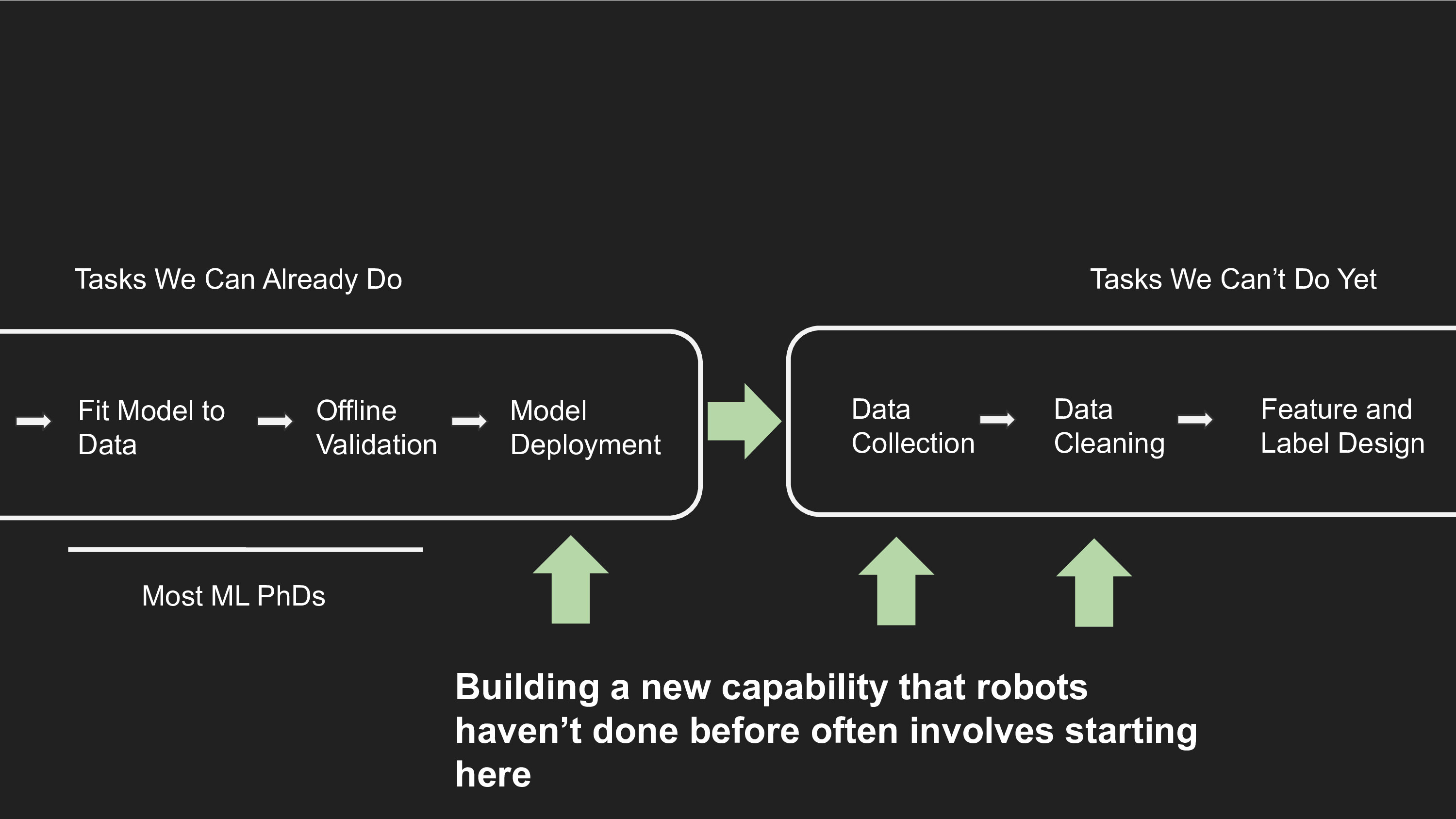
There is a delicate balance in choosing between understanding ML algorithms better, versus pushing towards a longer term goal of qualitative leaps in robotic capability. I also acknowledge that the deep learning revolution for robotics needs to begin with solving the easier tasks and then eventually working its way up to the harder problems. One way to accomplish both good science and long term robotics is to understand how existing algorithms break down in the face of harder data and tougher generalization demands encountered in new tasks.
Interesting Problems
Hopefully I've convinced you that end-to-end learning is full of opportunities to really get robotics right, but also rife with practical challenges. I want to highlight two interesting problems that I think are deeply important to pushing this field forward, not just for robotics but for any large-scale ML system.
A typical ML research project starts from a fixed dataset. You code up and train a series of ML experiments, then you publish a paper once you're happy with one of the experiments. These codebases are not very large and don't get maintained beyond the duration of the project, so you can move quickly and scrappily with little to no version control or regression testing.


Consider how this would go for a "lifelong learning" system for robotics, where you are collecting data and never throwing it away. You start the project with some code that generates a dataset (Data v1). Then you train a model with some more code, which compiles a Software 2.0 program (ckpt.v1.a). Then you use that model to collect more data (Data v2), and concatenate your datasets together (Data v1 + Data v2) to then train another model, and use that to collect a third dataset (Data v3), and so on. All the while you might be publishing papers on the intermediate results.
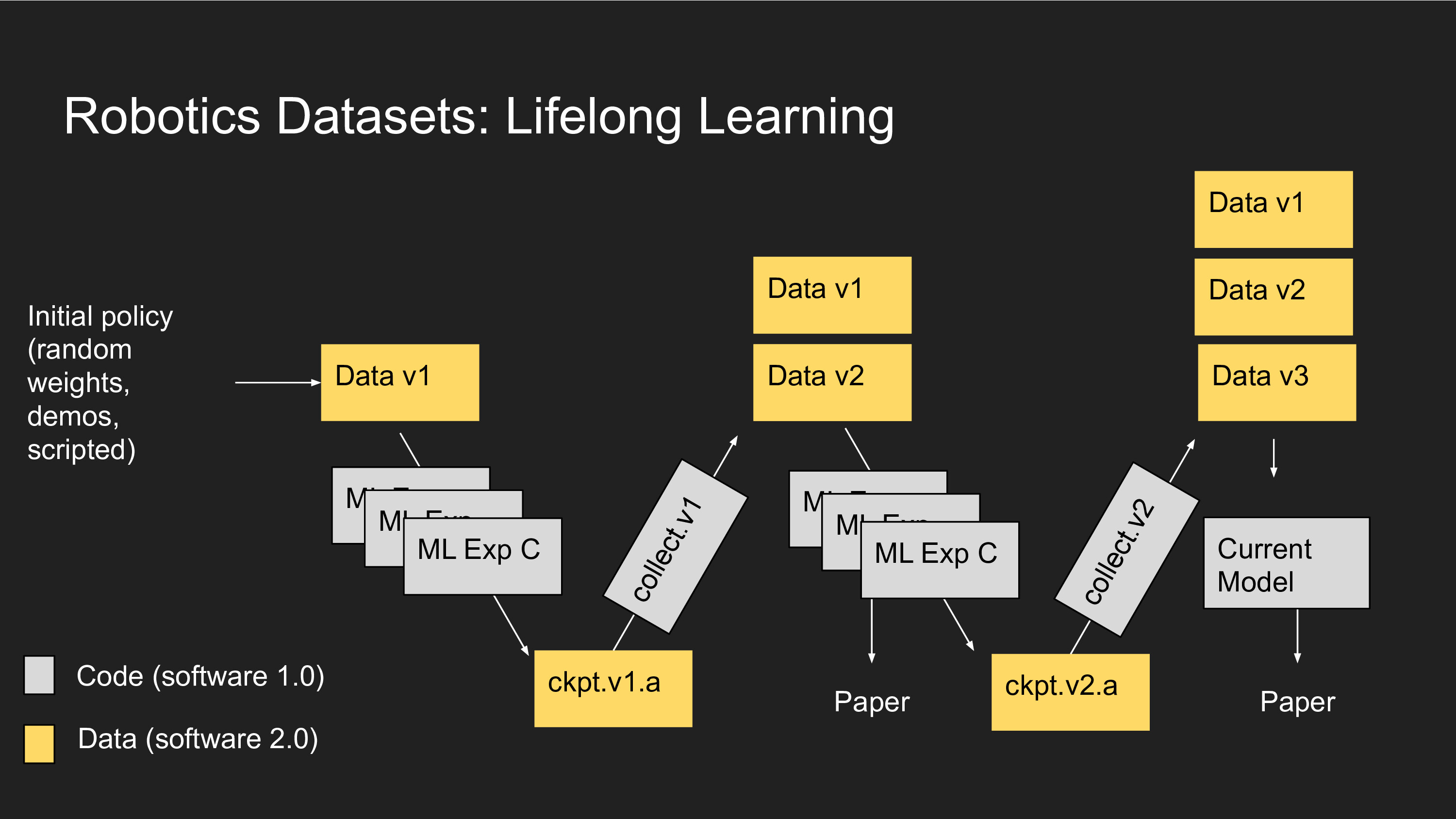
The tricky thing here is that the behavior of Software 1.0 and Software 2.0 code is now baked into each round of data collection, and the Software 2.0 code has assumptions from all prior data and code baked into it. The dependency graph between past versions of code and your current system become quite complex to reason about.
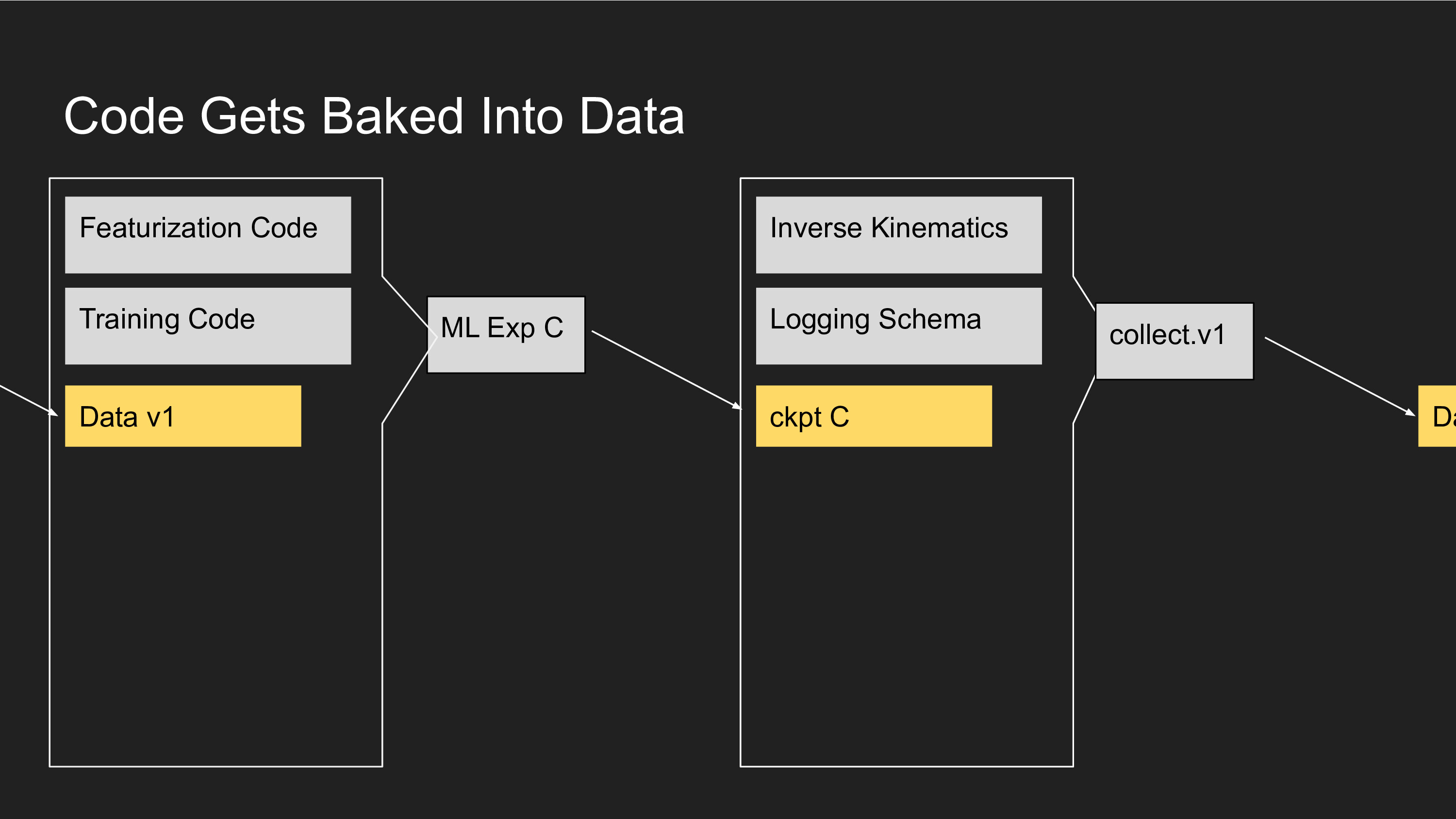
This only gets trickier if you are running multiple experiments and generating multiple Software 2.0 binaries in parallel, and collecting with all of those.
Let's examine what code gets baked into a collected dataset. It is a combination of Software 1.0 code (IK solver, logging schema) and Software 2.0 code (a model checkpoint). The model checkpoint itself is the distillation of a ML experiment, which consists of more Software 1.0 code (Featurization, Training code) and Data, which in turn depends on its own Software 1.0 and 2.0 code, and so on.
Here's the open problem I'd like to pose to the audience: how can we verify correctness of lifelong learning systems (accumulating data, changing code), while ensuring experiments are reproducible and bug free? Version control software and continuous integration testing is indispensable for team collaboration on large codebases. What would the Git of Software 2.0 look like?
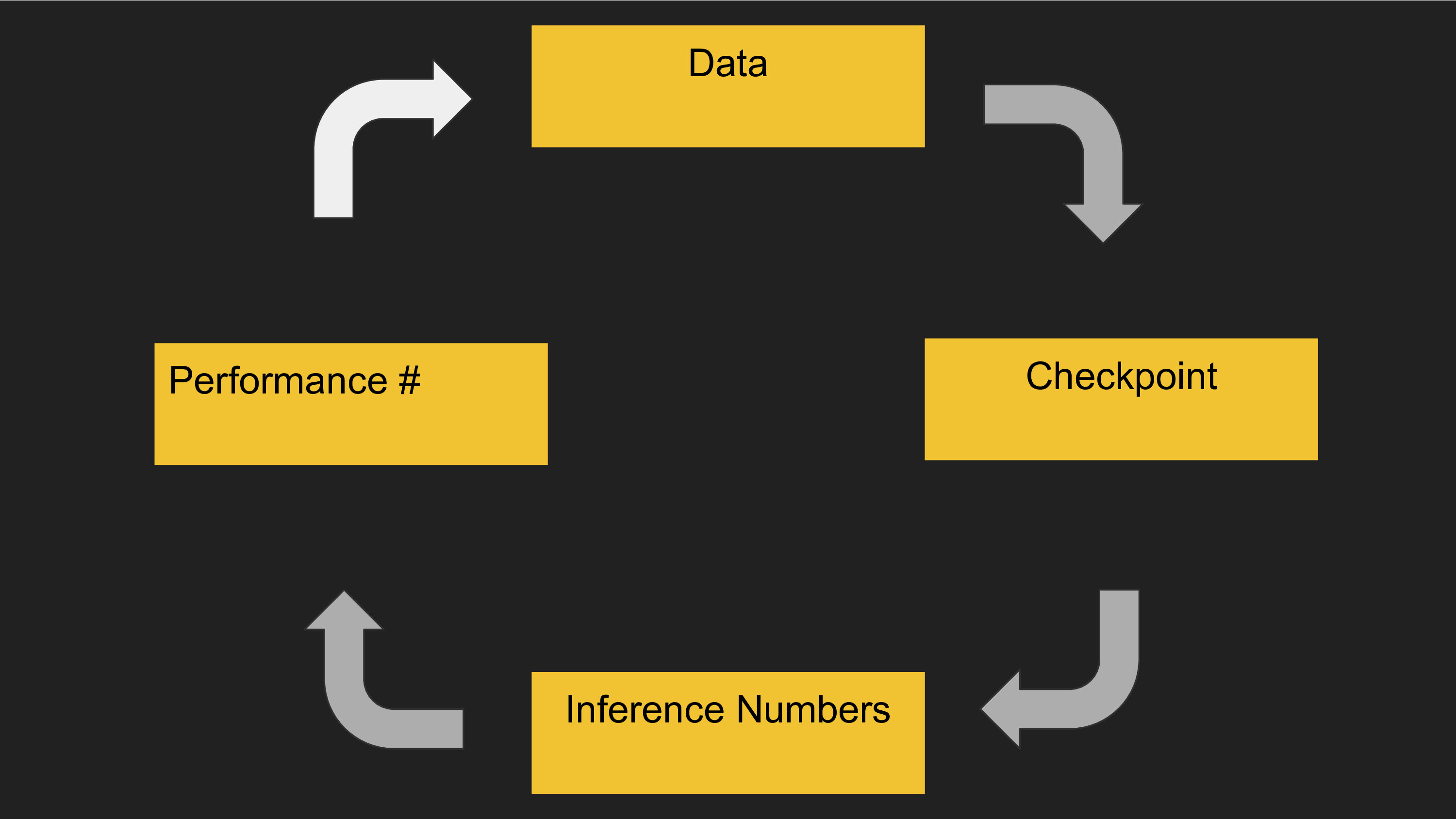
Here are a couple ideas on how to mitigate the difficulty of lifelong learning. The flywheel of an end-to-end learning system involves converting data to a model checkpoint, then a model checkpoint to predictions, and model predictions to a final real world evaluation number. That eval also gets converted into data. It's critical to test these four components separately to ensure there are no regressions - if one of these breaks, so does everything else.
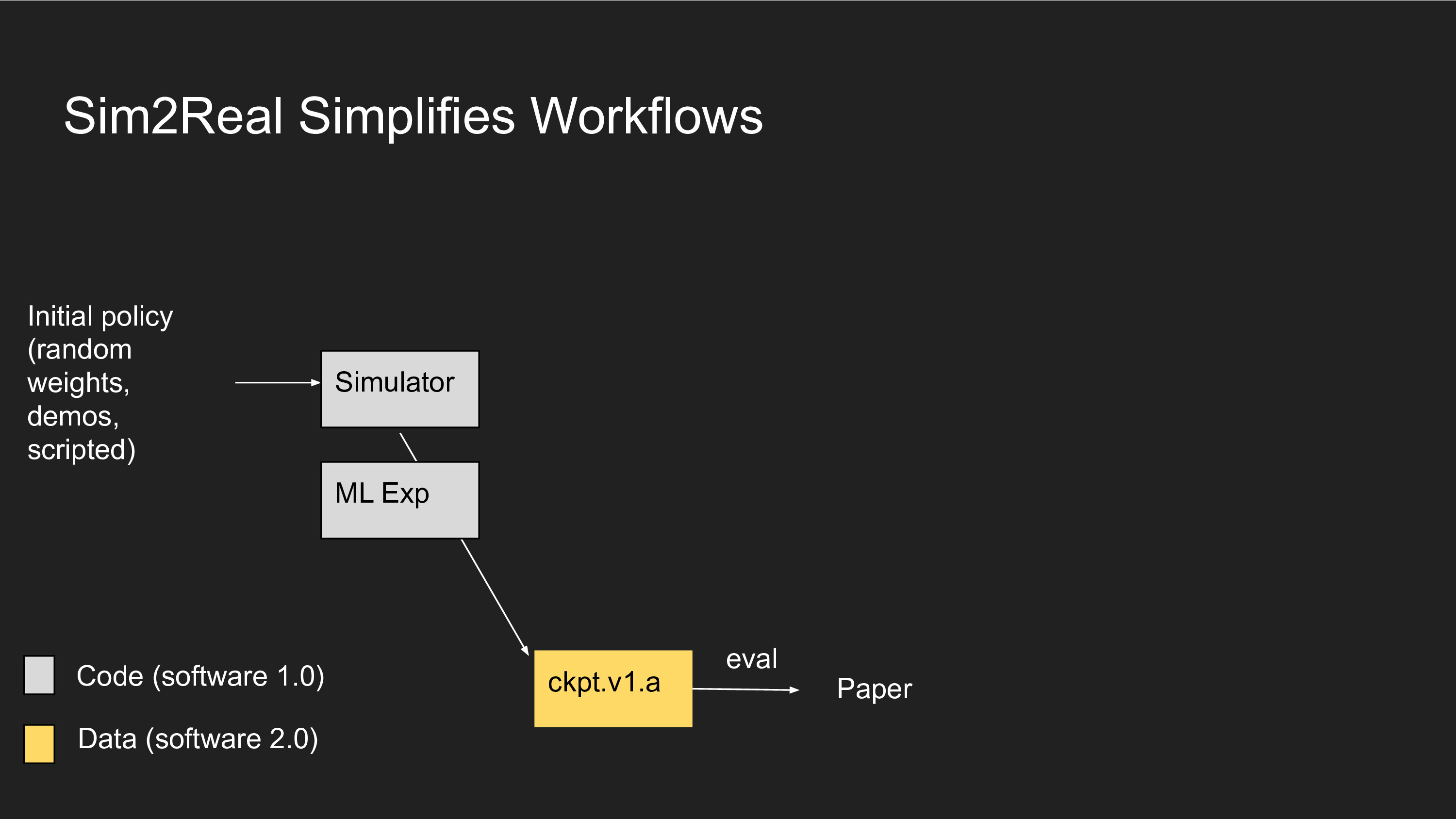
Another strategy is to use Sim2Real, where you train everything in simulation and develop a lightweight fine-tuning procedure for transferring the system to reality. We rely on this technique heavily at Google and I've heard this is OpenAI's strategy as well. In simulation, you can transmute compute into data, so data is relatively cheap and you don't have to worry about handling old data. Every time you change your Software 1.0 code, you can just re-simulate everything from scratch and you don't have to deal with ever-increasing data heterogeneity. You might still have to manage some data dependencies for real world data, because typically sim2real methods require training a CycleGAN.
Compiling Software 2.0 Capable of Lifelong Learning
When people use the phrase "lifelong learning" there are really two definitions. One is about lifelong dataset accumulation, and concatenating prior datasets to train systems that do new capabilities. Here, we may re-compile the Software 2.0 over and over again.
A stronger version of "lifelong learning" is to attempt to train systems that learn on their own and never need to have their Software 2.0 re-compiled. You can think about this as a task that runs for a very long time.
Many of the robotic ML models we build in our lab have goldfish memories - they make all their decisions from a single instant in time. They are, by construction, incapable of remembering what the last action they took was or what happend 10 seconds ago. But there are plenty of tasks where it's useful to remember:
- An AI that can watch a movie (>170k images) and give you a summary of the plot.
- An AI that is conducting experimental research, and it needs to remember hundreds of prior experiments to build up its hypotheses and determine what to try next.
- An AI therapist that should remember the context of all your prior conversations (say, around 100k words).
- A robot that is is cooking and needs to leave something in the oven for several hours and then resume the recipe afterwards.

Memory and learning over long time periods requires some degree of selective memory and attention. We don't know how to select which moments in a sequence are important, so we must acquire that by compiling a Software 2.0 program. We can train a neural network to fit some task objective to the full "lifetime" of the model, and let the model figure out how it needs to selectively remember within that lifetime in order to solve the task.
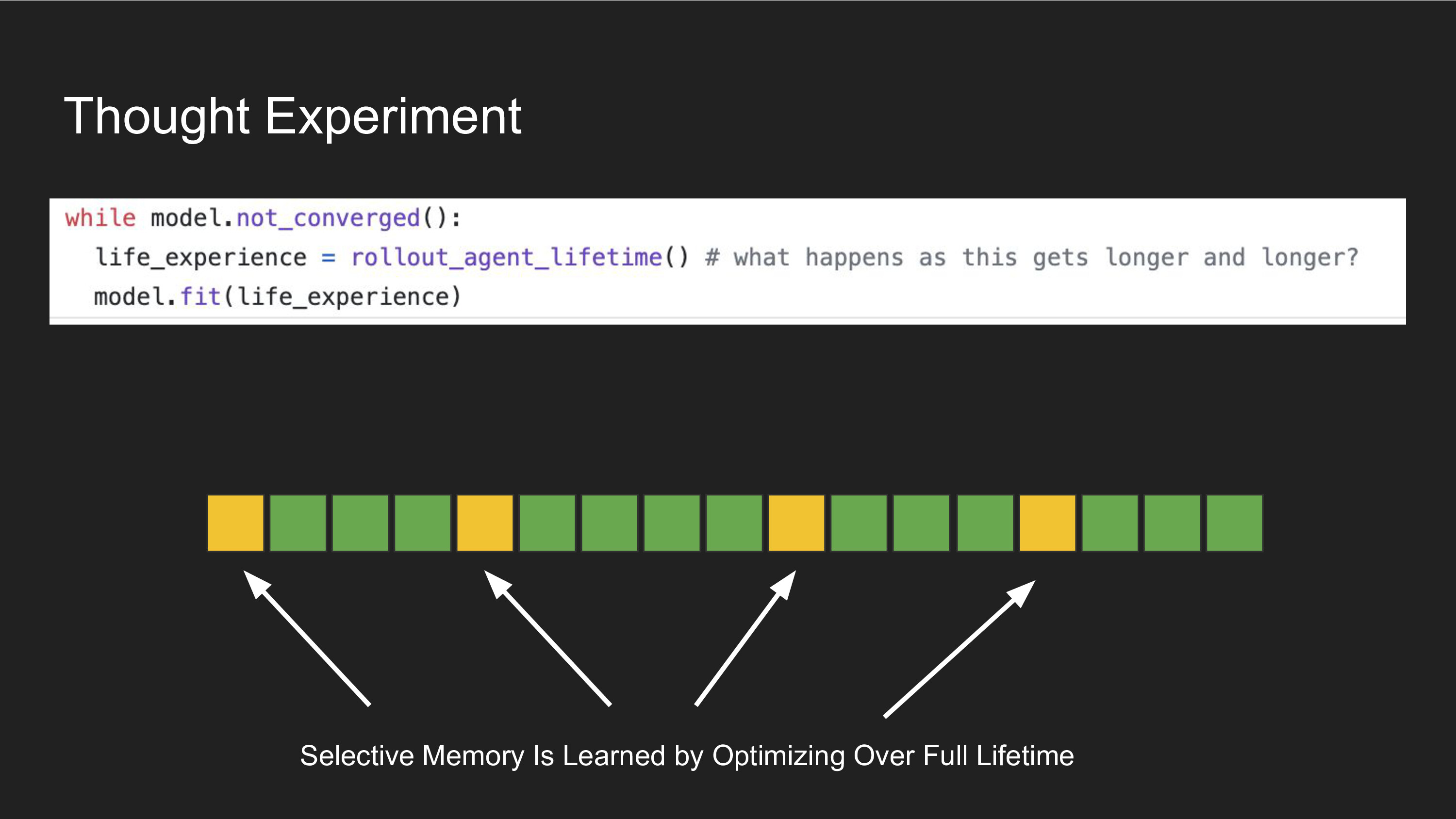
However, this presents a big problem: in order to optimize this objective, you need to run forward predictions over every step in the lifetime. If you are using backpropagation to train your networks, then you also need to run a similar number of steps in reverse. If you have N data elements and the lifetime is T steps long, the computational cost of learning is between O(NT) and O(NT^2), depending on whether you use RNNs, Transformers, or something in between. Even though a selective attention mechanisms might be an efficient way to perform long-term memory and learning, the act of finding that program via Software 2.0 compilation is very expensive because we have to consider full sequences.
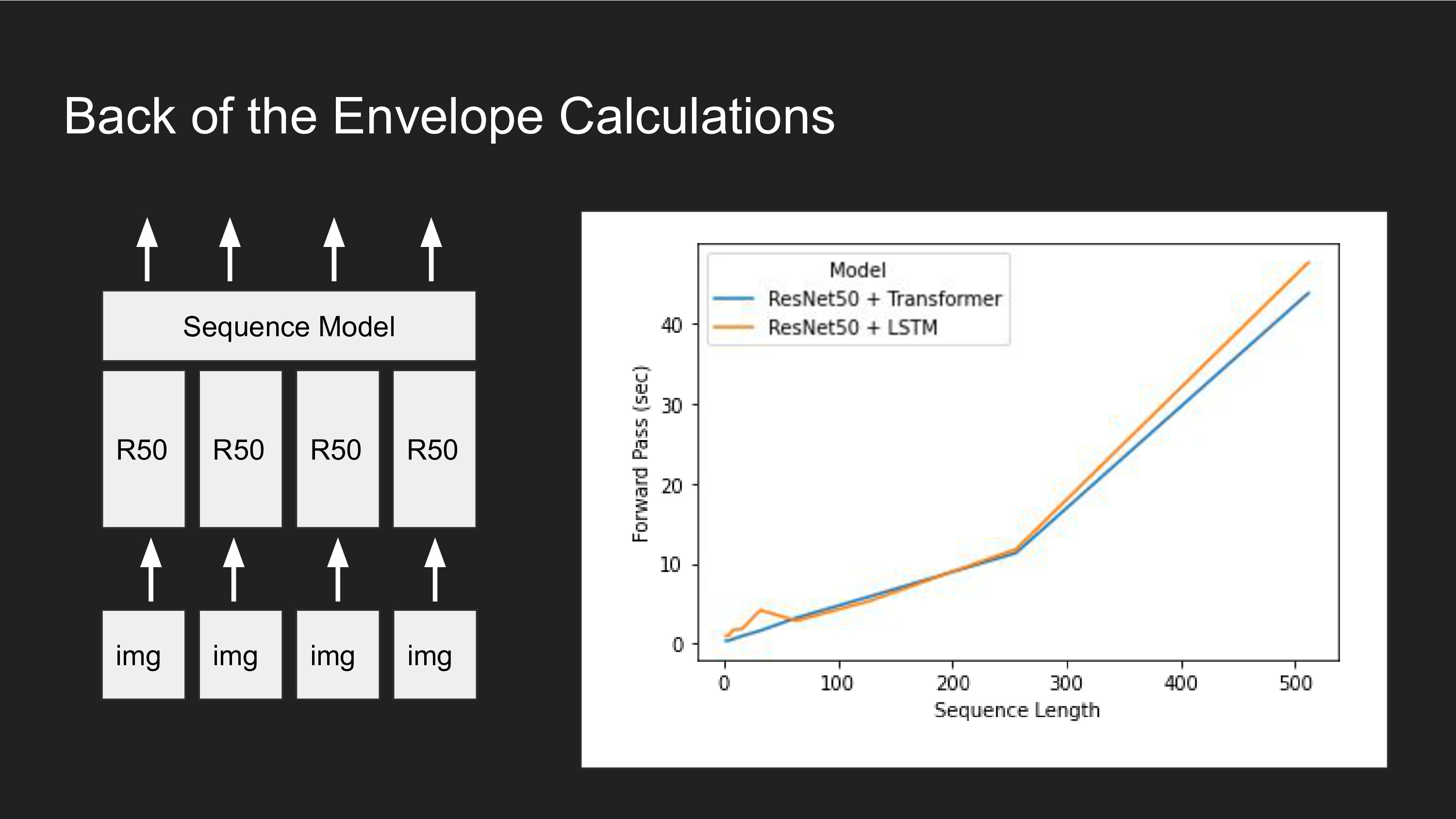
The second open-ended question I would like to pose is: how do we train a model to learn over a window T_small < T so taht it generalizes well to longer sequences of length T? How small can the ratio T_small/T be?
Train on Short Sequences and It Just Works
The optimistic take is that we can just train on shorter sequences, and it will just generalize to longer sequences at test time. Maybe you can train selective attention on short sequences, and then couple that with a high capacity external memory. Ideas from Neural Program Induction and Neural Turing Machines seem relevant here. Alternatively, you can use ideas from Q-learning to essentially do dynamic programming across time and avoid having to ingest the full sequence into memory (R2D2)

Hierarchical Computation
Another approach is to fuse multiple time steps into a single one, potentially repeating this trick over and over again until you have effectively O(log(T)) computation cost instead of O(T) cost. This can be done in both forward and backward passes - clockwork RNNs and Dilated Convolutions used in WaveNet are good examples of this. A variety of recent sub-quadratic attention improvements to Transformers (Block Sparse Transformers, Performers, Reformers, etc.) can be thought of as special cases of this as well.
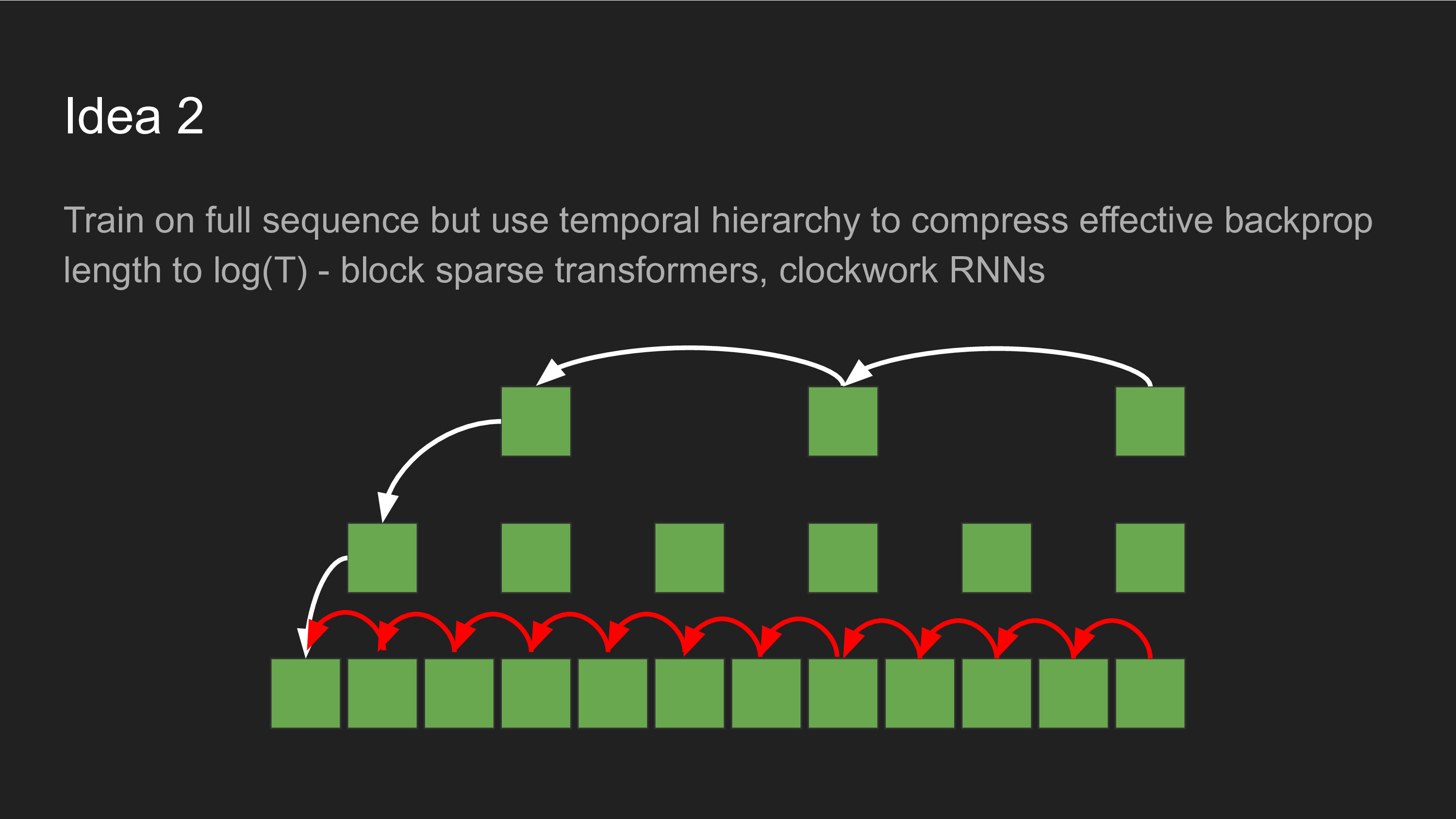
Parallel Evolution
Maybe we do need to just bite the bullet and optimize over the full sequences, but use embarassingly parallel algorithms to ammortize the time complexity (by distributing it across space). Rather than serially running forward-backward on the same model over and over again, you could imagine testing multiple lifelong learning agents simultaneously and choosing the best-of-K agents after T time has elapsed.

Interested In Working on This?
If you're interested in these problems, here's some concrete advice for how to get started. Start by looking up the existing literature in the field, pick one of these papers, and see if you can re-implement it from scratch. This is a great way to learn and make sure you have the necessary coding chops to get ML systems working well. Then ask yourself, how well does the algorithm handle harder problems? At what point does it break down? Finally, rather than thinking about incremental improvements to existing algorithms and benchmarks, constantly be thinking of harder benchmarks and new capabilities. Shoot me an email if you find something interesting!

Summary
- Three reasons why I believe in end-to-end ML for robotics: (1) it worked for other domains (2) fusing perception and control is a nice way to simplfiy decision making for many tasks (3) we can't define anything precisely so we need to rely on reality (via data) to tell us what to do.
- When it comes to improving our learning systems, think about the broader pipeline, not just the algorithmic and mathy learning part.
- Technical Challenge 1: how do we do version control for Lifelong Learning systems?
- Technical Challenge 2: how do we compile Software 2.0 that does Lifelong Learning? How can we optimize for long-term memory and learning without having to optimize over full lifetimes?