ML Mentorship: Some Q/A about RL
One of my ML research mentees is following OpenAI's Spinning up in RL tutorials (thanks to the nice folks who put that guide together!). She emailed me some good questions about the basics of Reinforcement Learning, and I wanted to share some of my replies on my blog in case it helps further other student's understanding of RL.
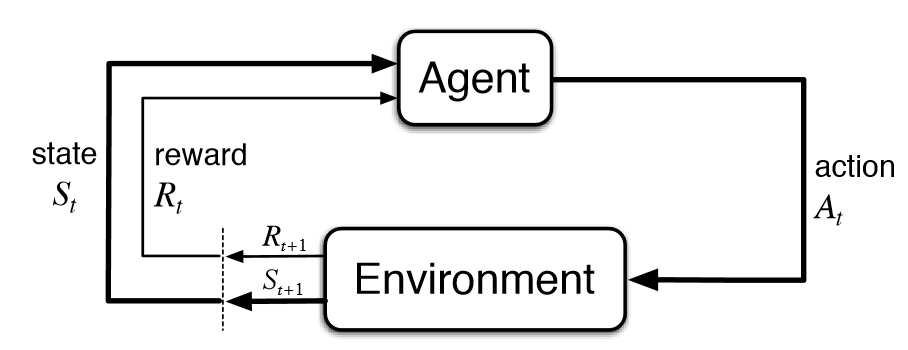
The classic Sutton and Barto diagram of a Markov Decision Process.
Your “How to Understand ML Papers Quickly” blog post recommended asking ourselves “what loss supervises the output predictions” when reading ML papers. However, in SpinningUp, it mentions that “minimizing the ‘loss’ function has no guarantee whatsoever of improving expected return” and “loss function means nothing.” In this case, what should we look for instead when reading DRL papers if not the loss function?
Policy optimization algorithms like PPO train by minimizing some loss, which in the most naive implementation is the (negative) expected return at the current policy's parameters. So in reference to my blog post, this is the "policy gradient loss" that supervises the current policy's predictions.
It so happens that this loss function is defined with respect to data \(D(\pi^i)\) sampled by the current policy, rather than data sampled i.i.d from a fixed / offline dataset as commonly done in supervised learning. So if you change the policy from \(\pi^i \to \pi^{i+1}\), then re-computing the policy gradient loss for \(\pi^{i+1}\) requires collecting some new environment data \(D(\pi^{i+1})\) with \(\pi^{i+1}\). Computing the loss function has special requirements (you have to annoyingly gather new data every time you update), but at the end of the day it is still a loss that supervises the training of a neural net, given parameters and data.
On "loss function means nothing": the Spinning Up docs are correct in saying that the loss you minimize is not actually the evaluated performance of the policy, in the same way that minimizing cross entropy loss maximizes accuracy while not telling you what the accuracy is. In a similar vein, the loss value for \(\pi^i,D(\pi^{i})\) is decreased after a policy gradient update. You can assume that if your new policy sampled the exact same trajectory as before, the resultant reward would be the same, but your loss would be lower. Vice versa, if your new policy samples a different trajectory, you can probably assume that there will be a monotonic increase in reward as a result of taking each policy gradient step (assuming step size is correct and that you could re-evaluate the loss under a sufficiently large distribution).
However, you don't know how much decrease in loss translates to increase in reward, due to non-linear sensitivity between parameters and outputs, and further non-linear sensitivity between outputs and rewards returned by the environment. A simple illustrative example of this: a fine-grained manipulation task with sparse rewards, where the episode return is 1 if all actions are done within a 1e-3 tolerance, and 0 otherwise. A policy update might result in each of the actions improving the tolerance from 1e-2 to 5e-3, and this policy achieves a lower "loss" according to some Q function, but still has the same reward when re-evaluated in the environment.
Thus, when training RL it is not uncommon to see the actor loss go down but the reward stay flat, or vice versa (the actor loss stays flat but the reward goes up). It's usually not a great sign to see the actor loss blow up though!
Why in DRL, do people frequently set up algorithms to optimize the undiscounted return, but use discount factors in estimating value functions?
See this StackExchange answer. In addition to avoiding infinite sums from a mathematical perspective, the discount factor actually serves as an important hyperparameter when tuning RL agents. It biases the optimization landscape so that agents prefer the same reward sooner than later. Finishing an episode sooner also allows agents to see more episodes, which indirectly improves the amount of search and exploration a learning algorithm can do. Additionally, discounting produces a symmetry-breaking effect that further reduces the search space. In a sparse reward environment with a \(\gamma=1\) (no discounting), an agent would be equally happy to do nothing on the first step, and then complete the task vs. do the task straight away. Discounting makes the task easier to learn because the agent can learn that there is only one preferable action at the first step.
In model-based RL, why does embedding planning loops into policies makes model bias less of a problem?
Here is an example that might illustrate how planning helps:
Given a good Q function \(Q(s,a)\), you can recover a policy \(\pi(a\vert s)\) by performing a search procedure \(\text{argmax}_a Q(s,a)\) to recover the best action that results in the best expected (discounted) future returns. A search algorithm like grid search is computationally expensive, but guaranteed to work because it will cover all the possibilities.
Imagine instead of search, you use a neural network "actor" to amortize the "search" process into a single pass through a neural network. This is what Actor-Critic algorithms do: they learn a critic and use the critic to learn an actor, which performs "amortized search over the argmax \(Q(s,a)\)".
Whenever you can use brute force search on the critic instead of an actor, it is better to do so. This is because an actor network (amortized search) can make mistakes, while brute force is slow but will not make a mistake.
The above example illustrates the simplest example of a 1-step planning algorithm, where "planning" is actually synonymous with "search". You can think about the act of searching for the best action with respect to \(Q(s,a)\) as being equivalent to "planning for the best future outcome", where \(Q(s,a)\) evaluates your plan.
Now imagine you have a perfect model of dynamics, \(p(s^\prime \vert s,a)\), and an okay-ish Q function where it has function approximation errors in some places. Instead of just selecting the best Q value and action at a given state, the agent can now consider the future state and consider the Q values that one encounters at the next set of actions. By using a plan and an "imagined rollout" of the future, the agent can query \(Q(s,a)\) along every state in the trajectory, and potentially notice inconsistencies with Q functions. For instance, Q might be high at the beginning of the episode but low at the end of the episode despite taking the greedy action at each state. This would immediately tell you that the Q function is unreliable for some states in the trajectory.
A well-trained Q function should respect the Bellman equality, so if you have a Q function and a good dynamics model, then you can actually check your Q function for self-consistency at inference time time to make sure it satisfies Bellman equality, even before taking any actions.
One way to think of a planning module is that it "wraps" a value function \(Q_\pi(s,a)\) and gives you a slightly better version of the policy, since it uses search to consider more possibilities than the neural-net amortized policy \(\pi(a\vert s)\). You can then take the trajectory data generated by the better policy and use that to further improve your search amortizer, which yields the "minimal policy improvement technique" perspective from Ferenc Huszár.
When talking about data augmentation for model-free methods, what is the difference between “augment[ing] real experiences with fictitious ones in updating the agent” and “us[ing] only fictitious experience for updating the agent”?
If you have a perfect world model, then all you need is to train an agent on "imaginary rollouts" and then it will be exactly equivalent to training the agent on the real experience. In robotics this is really nice because you can train purely in "mental simulation" without having to wear down your robots. Model-Ensemble TRPO is a straightforward paper that tries these ideas.
Of course in practice, no one ever learns a perfect world model, so it's common to use the fictitious (imagined) experience as a supplemental experience to real interaction. The real interactions data provide some grounding in reality for both the imagination model and the policy training.
How to choose the baseline (function b) in policy gradients?
The baseline should be chosen to minimize the variance of gradients while keeping the estimate of the learning signal unbiased. Here is a talk that covers that stuff in more detail, you can also google terms like "variance reduction policy gradient" more and "control variates reinforcement learning". I also have a blog post on variance reduction, which also discusses control variates.
Consider episode returns for 3 actions = [1, 10, 100]. Clearly the third action is by far the best, but if you take a naive policy gradient, you end up increasing the likelihood of the bad actions too! Typically \(b=V(s)\) is sufficient, because it turns the \(Q(s,a)−V(s)\) into advantage \(A(s,a)\), which has the desired effect of increasing the likelihood of good actions, keeping the likelihood of neutral actions the same, and decreasing the likelihood of bad actions.
How to better understand target policy smoothing in TD3?
In actor-critic methods, both the Q function and actor are neural networks, so it can be very easy to use gradient descent to find a region of high curvature in the Q function where the value is very high. You can think of the actor as a generator and a critic as a discriminator, and the actor learns to "adversarially exploit" regions of curvature in the critic so as to maximize the Q value without actually emitting meaningful actions.
All three of the tricks in TD3 are designed to mitigate the problem of the actor adversarially selecting an action with a pathologically high Q value. By adding noise to the input to the target Q network, it prevents the "search" from finding exact areas of high curvature. Like Trick 1, it helps make the Q function estimates more conservative, thus reducing the likelihood of choosing over-estimated Q values.
A Note on Categorizing RL Algorithms
RL is often taught in a taxonomic layout, as it helps to classify algorithms based on whether they are "model based vs. model-free", "on-policy vs. off-policy", "supervised vs. unsupervised". But these categorizations are illusory, much like the Spoon in the Matrix. There are actually many different frameworks and schools of thought that allow one to independently derive the same RL algorithms, and they cannot always be neatly classified and separated from each other.
For example, it is possible to derive actor critic algorithms from both on-policy and off-policy perspectives.
Starting from off-policy methods, you have DQN which use the inductive bias of Bellman Equality to learn optimal policies via dynamic programming. Then you can extend DQN to continuous actions via an actor network, which arrives at DDPG.
Starting from on-policy methods, you have REINFORCE, which is vanilla policy gradient algorithm. You can add a value function as a control variate, and this requires learning a critic network. This again re-derives something like PPO or DDPG.
So is DDPG an on-policy or off-policy algorithm? Depending on the frequency with which you update the critic vs. the actor, it starts to look more like onpolicy or offpolicy update. My colleague Shane has a good treatment of the subject in his Interpolated Policy Gradients paper.