To Understand Language is to Understand Generalization
We all want ML models to generalize better, but defining "generalization" is hard. I suggest that the structure of language is the structure of generalization. If language models also capture the underlying structure of generalization vis-à-vis language, then perhaps we can use language models to "bolt generalization" onto non-verbal domains, such as robotics.
In my essay "Just ask for Generalization", I argued that some optimization capabilities, such as reinforcement learning from sub-optimal trajectories, might be better implemented by generalization than by construction. We have to generalize to unseen situations at deployment time anyway, so why not focus on generalization capability as the first class citizen, and then "just ask for optimality" as an unseen case? A corollary to this design philosophy is that we should discard inductive biases that introduce optimization bottlenecks for "the data sponge": if an inductive bias turns out to be merely "data in disguise", it may not only cease to provide a benefit in the high data regime, but actually hinder the model on examples where the inductive bias no longer applies.
Pushing as much human-written code to "language + deep learning magic" sounds like a lot of fun, but how does a practitioner execute this "just-ask-for-generalization" recipe? If we want to infer optimal behavior via a deep neural net without training explicitly for it, we need to answer hard questions: given a model family and some training data, what kinds of test examples can we expect the model to generalize to? How much is "too much to ask for"?
And how do you define generalization, anyway? ML theory gives us some basic definitions like generalization gap and excess risk (i.e. the difference between training and testing losses), but such definitions are not useful for estimating what it takes to achieve a qualitative degree of capability not seen in the training data. For example, if I am training a household robot to be able to wash dishes in any home, how many homes do I need to collect training data in before the learned policy starts to work in any kitchen? This practical question comes in many formal disguises:
- "What data is out-of-distribution?"
- "Is my model + data robust to adversarial examples?"
- "How can we train models to know what they don't know?"
- "What is extrapolation?"
Like the parable of the blind men and the elephant, computer scientists have come up with different abstract frameworks to describe what it would take to make our machines smarter: equivariance algebra, causal inference, disentangled representations, Bayesian uncertainty, hybrid symbolic-learning systems, explainable predictions, to name a few.
I'd like to throw in another take on the elephant: the aforementioned properties of generalization we seek can be understood as nothing more than the structure of human language. Before you think "ew, linguistics" and close this webpage, I promise that I'm not advocating for hard-coding formal grammars as inductive biases into our neural networks (see paragraph 1). To the contrary, I argue that considering generalization as being equivalent to language opens up exciting opportunities to scale up non-NLP models the way we have done for language.
Compositionality in Language
Hupkes et al. 2020 discusses a few different aspects of "compositionality" in language models. Language is nothing more than the composition of a discrete set of tokens, so what the authors are really doing is specifying a grammar on how the smallest units of discrete meaning (words) fit together to form new meanings, i.e. the structure of language itself. Here is a table in which I've paraphrased the definitions and provided some training examples and test-time capabilities.
| Generalization Type | Definition | Training Examples | Testing Examples |
Systematicity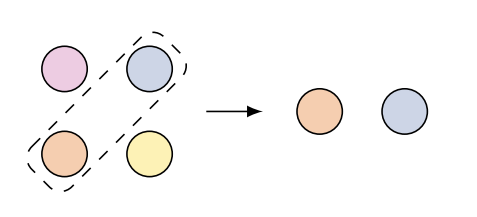 |
Recombine constituents that have not been seen together during training | {"Bob ate pizza", "Alice ran home"} | "Bob ran home" |
Productivity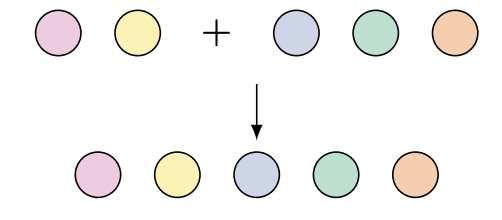 |
Test sequences longer than ones seen during training | books with 100k-200k words. | books with 200k+ words. |
Substitutivity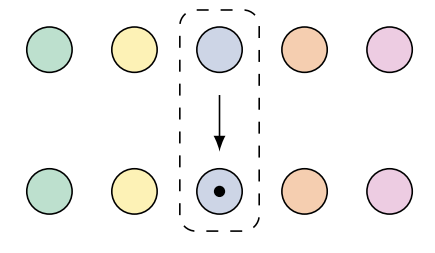 |
Meaning of an expression is unchanged if a constituent is replaced with something of the same meaning | "bob ate pizza for lunch" | "bob had Dominos at noon" taken to mean (almost) the same thing |
Localism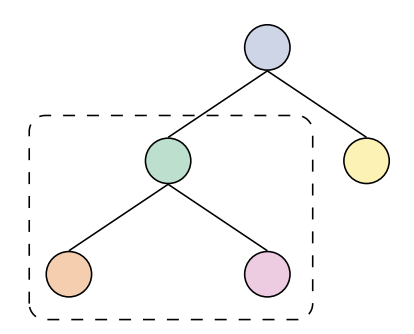 |
The meaning of local parts are unchanged by the global context. | Arithmetic tasks like {(5)-4, (2+3)} | (2+3)-4 : (2+3) locally evaluates to 5, then 5-4 locally evaluates to 1. (2+3) representation not influenced by the presence of -4. |
Overgeneralization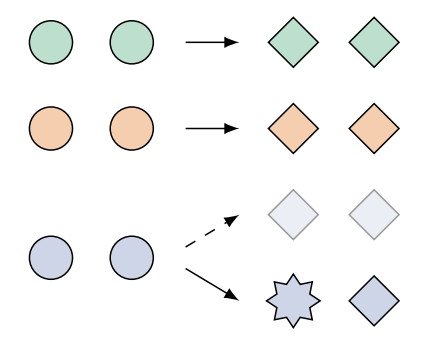 |
Correctly handle exceptions to rules and patterns | {live->lived, laugh->laughed, love->loved} | {kill->killed,break->broke (not breaked)} |
Compositionality in Everything Else
Hupkes' categorizations of compositionality can be applied to non-NLP domains as well. In "A Survey of Generalization in Deep Reinforcement Learning", the authors provide an intuition of how these categorizations can be applied to a robotic block-stacking task:
- Systematicity - Stack blocks in new configurations not seen in training
- Productivity - Stacking more blocks than was done in training
- Substitutivity - Stacking blocks it hasn't seen before (e.g. understanding that block color does not affect physical properties)
- Localism - Position of far-away objects do not affect behavior for stacking two blocks that are close together.
- Overgeneralization - the robot trains on stacking cubes, and knows not to stack a cylindrical block identically to the way it would stack a cube.
None of the above tasks involve understanding language, and yet the structures underpinning generalization - systematicity, productivity, substitutivity, localism, overgeneralization - are found here as well.
Perhaps we can cast other research around of "improving ML generalization" as special cases of language modeling. Consider "disentangled representations" research, whereby semantic attributes of data can be separately understood as discrete, standalone concepts. Your computer vision model can train on "green grass", and "red apple", and ideally would understand what "red grass" means even though it has never encountered that concept in the training data.
If a "style" \(\in A\) and "shape" \(\in B\) vector are "disentangled representations", then \(A \times B\) forms a simple vector space, or toy grammar, that your model ought to understand. We might combine the "red" concept vector with the "grass" concept vector and then decode it into an image with a conditional generative model \(p(\text{image} \vert a, b)\). In a robotic setting. we might train a robot that disentangles objects from skills, and specify goals by providing it with two inputs: a "skill categorical vector" (pick) and an "object categorical vector" (shoe). These sorts of simple two-word grammars are enough if you want to build a Face filtering app (e.g. combine me with "female face") or a pick-and-place robot, but a logical step to furthering disentangled representations research is to combine "disentangled concepts" in much more open-ended, arbitrary ways beyond orthogonal attributes.
Do you know what else are "disentangled, standalone concepts"? Words! If we venture away from toy compositional grammars towards the grammatical structure of natural language, we can now ask a generative model to "draw red grass where the sun is shining and purple grass where it is in shade and a horse eating the red grass". We can tell a robot to "pick up the leftmost object that is not a cup." Natural language permits us to do everything we can communicate to another person: embed logical predicates, fuzzy definitions, precise source code, and even supplement knowledge that the model does not know ahead of time ("Blickets are red with spikes, pick up a blicket").
Defining Fuzzy Concepts with Language Models
The 5-way categorization introduced by Hupkes plausibly describes the basic structures of language, but there are limits to language-based reasoning. If a robot is trained to "stack many blocks", and "wash a dish", and we instruct it to "wash many dishes", is that a test of systematicity (combining "many" and "dish" concepts from the training data)? Or is it testing productivity (repeated extension of the "wash a dish" task)? Does it really matter?
Another ambiguous example: when testing productivity, language comes with a fairly obvious choice for the extrapolation axis: the number of tokens in the input sequence. But one could also imagine productivity being measured as the length of the output sequence (what is the longest story the book could write?), the depth of a parse tree (how many nested parentheses can your NLP model manage the scope for?), or any arbitrary semantic measure (what is the maximum number of characters the model can write a story about)? The distinctions between systematicity and productivity start to break down here again, especially when it comes to compositionality on higher-level concepts beyond the individual token level. As with all semantics, the precise boundaries of anything - even definitions around the basic structures of language itself - become fuzzy if you look too hard. It's sort of like a Heisenberg's Uncertainty principle for semantics.
Unlike most formal grammars, natural language is capable of handling some fuzziness and ambiguity, insofar as it is good enough for human communication and survival. My analogy to the uncertainty principle ("sort of like…") is a case in point. The best formal definition of an "image of a cat" we have today is a neural network classifier trained on a lot of human labels - a person simply can't write down that definition in a sufficiently precise way. If defining cat images is best done from data and machine learning, then it begs the question of whether richer semantic ontologies (especially around generalization) are better defined from data as well. If a model understands human language well enough, then we can use it to venture beyond precise toy grammars into a truly vast, fuzzy space of capabilities like "please imitate another agent pretending to be you", as I suggested in "Just ask for Generalization".
Bolt-on Generalization
When it comes to combining natural language with robots, the obvious take is to use it as an input-output modality for human-robot interaction. The robot would understand human language inputs and potentially converse with the human. But if you accept that "generalization is language", then language models have a far bigger role to play than just being the "UX layer for robots". We should regard language capability as a substrate for generalization in any machine learning domain.
Linguistic relativists say that language is not only the primary way we communicate to each other, it is also the way we communicate to ourselves when thinking. Language is generalization is cognition.
We are still in the early days of imbuing our robots with evidence of linguistic relativity, but there are some exciting promising results in this direction. The paper Pretrained Transformers as Universal Computation Engines (Lu et al 21) showed that the internal structure of pre-trained language models can be frozen, and used as-is to perform a variety of non-language tasks, like numerical computation, protein folding, and vision. The internal representations are only trained on language domains, with the input and output embeddings re-learned for each fine-tuning task.
This is wildly exciting, because it suggests that it might be possible to improve generalization simply by scaling up language data, rather than collecting a lot of task-specific data. Perhaps language models can imbue other ML models with systematicity, productivity, substitutivity in an infintiely-composable way, because they already acquired them when training on language datasets.
More evidence for this idea comes from our recent BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning research paper, where we use language data in place of real robot data to get the robot to perform new tasks it hasn't trained on. The robot never saw the bottle and tray in the same scene and was never trained on the "place bottle in the tray" task, and yet it can zero-shot the task. The policy merely conditions on pre-trained sentence embeddings, so the language model is doing the heavy lifting of task-level generalization.

Interestingly enough, we also tried to teach the robot to generalize to the same held-out tasks by conditioning on task embeddings of humans performing the task. We struggled for years to get it working, and it wasn't until we explicitly aligned the video embeddings to match language space that we were able to see held-out task generalization on human videos.
There are some ML research tailwinds that make this idea of "bolt-on generalization from language models" increasingly easy to try. Transformers have been the architecture-of-choice for modeling language for a few years now, but in the last year we've seen a rapid consolidation of computer vision architectures around transformers as well. Today it is possible to train both state-of-the-art language and state-of-the-art vision models with pretty much the same architecture (e.g. ViT), so I think that we will start to see transformers trained for perception benchmarks start to re-use language datasets as an extra source of data. Here's a prediction (epistemic confidence 0.7): within the next 5 years, we'll see a state-of-the-art model for a computer vision benchmark that does not involve natural language (e.g. ImageNet classification), and that model uses knowledge from internet-scale natural language datasets (by either training directly on NLP datasets or indirectly via re-using an existing language model).
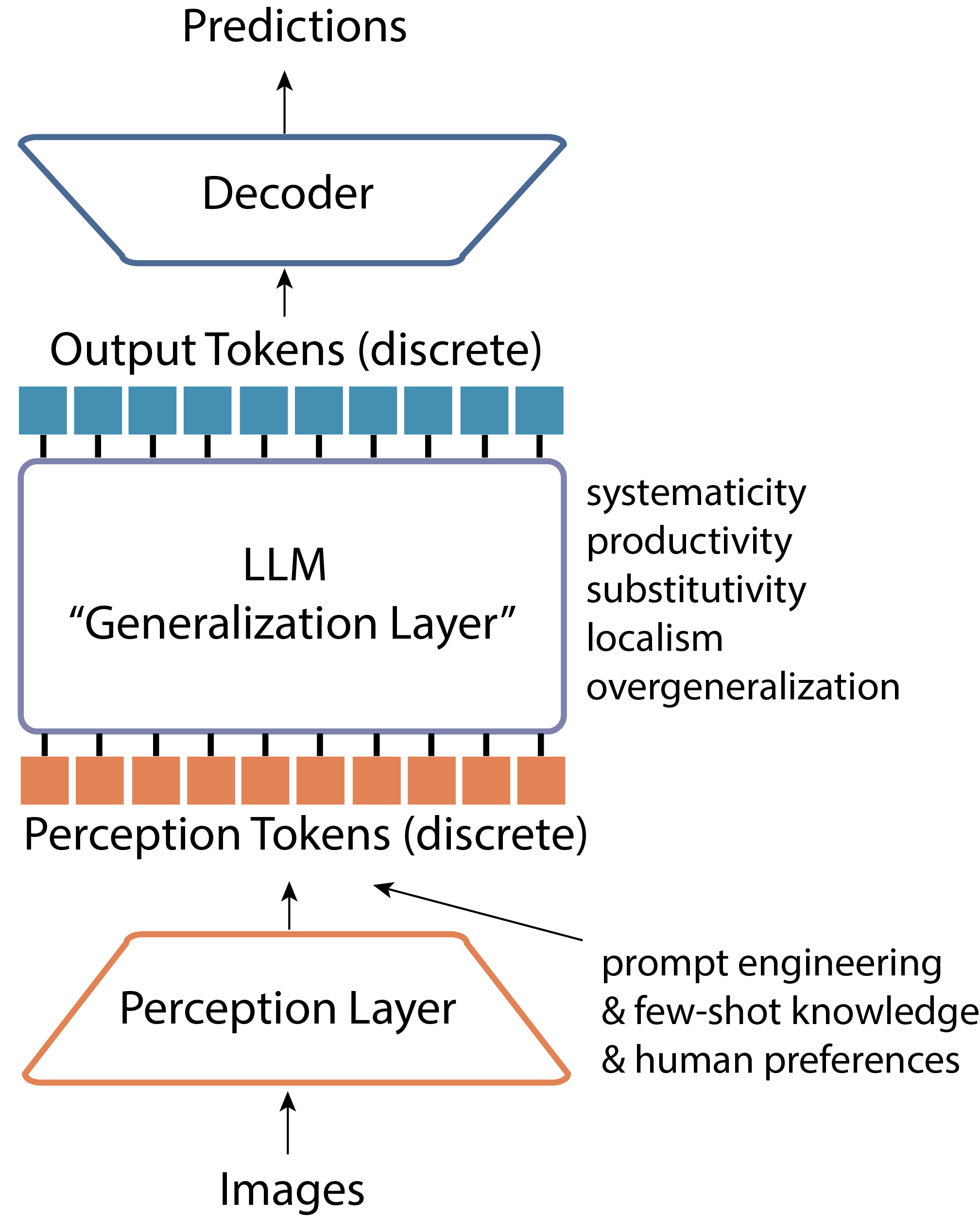
A sketch of what I think neural architectures of the future will look like, inspired by the Universal Computation Engine and ViT papers: you have a large language model that acts as "bolt-on-generalization layer" for a target task domain, lightweight encoder layers to tokenize the input into something that can capture "word-level" semantics, and lightweight output decoders that transform the "generalization module" output tokens into the right prediction space. Additionally, because the core of the model is a standard transformer, it is simple to pass in additional natural language tokens for goal conditioning or extra human knowledge.
Summary
Language Models are far from perfect even when restricted to NLP tasks, and I don't mean to suggest that they are ready today for solving ML once and for all. Rather, I am optimistic that language models will continue to get better, and with improved linguistic capability comes better generalization in other non-NLP domains.
- The structure of language is the structure of generalization.
- Formal grammars for language run up against a "semantic uncertainty principle", so let's rely on language models to represent language (and therefore, the structure of generalization).
- Let's use large language models to "bolt on generalization" to non-NLP domains. Some preliminary evidence (the Universal Computation Engines paper) suggests that it can work.
My friend Elijah invited me to give a talk at his company's algorithms seminar and I shared an early draft of these ideas there. Here is a recording on YouTube.
Citation
If you want to cite this blog post, you can use:
@article{jang2021language,
title = "To Understand Language is to Understand Generalization",
author = "Jang, Eric",
journal = "evjang.com",
year = "2021",
month = "Dec",
url = "https://evjang.com/2021/12/17/lang-generalization.html"
}
Q/A
How does this relate to Chomsky's ideas of innate language capability and Universal Grammars?
Chomsky has a lot more to say than a one-line "language is innate", but the gist is that humans are born with some innate linguistic capability. At face value, I agree with this since it follows from 1) linguistic relativity 2) equivalence between generalization and language 3) humans are born with some ability to generalize, even if what they are generalizing is their learning ability.
Where there is more controversy is how much linguistic capability is innate, and whether learning is distinct from language. If you believe that generalization is language, then maybe it isn't.
Also, the degree to which a capability is innate tells us nothing of our ability to hard-code it correctly. For instance, humans may be innately primed to dislike insects and snakes, but we might have to resort to function approximation from data if we wanted to build such an innate prior. For me, it is less about what is genetically or developmentally innate in animals, but more of whether we want to hard-code with formal structures vs. acquiring the structure via function approximation.
If linguistic capability is important for generalization, why not add more hard-coded linguistic rules into our neural networks so that they can perform more robust reasoning?
Gary Marcus has an excellent quote from The Next Decade in AI:
"The trouble is that GPT-2’s solution is just an approximation to knowledge, and not substitute for knowledge itself. In particular what it acquires is an approximation to the statistics of how words co-occur with one another in large corpora—rather than a clean representation of concepts per se. To put it in a slogan, it is a model of word usage, not a model of ideas, with the former being used as an approximation to the latter. Such approximations are something like shadows to a complex three-dimensional world"
Where Marcus sees "meaning = co-occurence statistics" as problematic for the purposes of building robust AI systems, I see this as a preliminary vindication of the Distributional semantics hypothesis. The meaning of words are nothing more than how they are used. Even if there was meaning independent of anthropomorphic usage (e.g. the concepts of life and death probably mean something to most animals), humans lack the ability to implement those concepts formally. That's not to suggest we should be content with defining everything as is found on the Internet, as some word co-occurences around race and gender and class are problematic for society. But it is helpful to understand that the meaning of words are derived from their usage, and not the other way around.