How Can We Make Robotics More like Generative Modeling?
Comparing the fields of generative modeling and robotic deep learning, and what we might do to speed up the pace of robotics research.
I recently gave a talk (YouTube) at the RSS'22 L-DOD workshop. Here's a lightly edited transcript and slides of the talk in blog form.
This talk is not so much about how we take gradient steps to train robots, but rather how we as researchers and engineers can iterate effectively on these systems as we scale them up.
Since this is a workshop about large offline datasets for robotic learning, I don't need to convince the audience that what matters most for making capable robots is having high quality data. Diverse data can help your neural networks handle situations not seen at training time. In the broader context of machine learning, people call this "out of distribution generalization (OoD)". In robotics we call it "operating in unstructured environments". They literally mean the same thing.
We believe in the simplicity and elegance of deep learning methods, and evidence from the last decade has shown that the recipe works. Here are some examples of large-scale learning robots I've built while I was at Google Brain:

- Qt-Opt can grasp objects not seen during training.
- Grasp2Vec is goal-conditioned and can grasp objects not seen during training.
- BC-Z is language-conditioned manipulation of objects, generalizing to unseen language commands
- Door opening from visuomotor policies and generalizing to unseen doors.
- SayCan can do even more language commands and also use language models for planning.
I'm not even going to cover how their learning algorithms work, because that's not important. What really matters is that once you have a large diverse dataset, almost any mix of learning techniques (supervised, unsupervised, offline RL, model-based) should all work. I suspect that for any of these datasets, if you applied a different learning method to the same data, you could probably get the robot to do something reasonable.
The Grass is Greener in Generative Modeling
All this progress is really exciting, pointing to a future in which we'll have robots doing lots of things in unstructured environments. But there's something that's been bothering me lately…
… just a few cubicles away, progress in generative modeling feels qualitatively even more impressive, especially since the development of GPT-3 and Scaling Laws.

The salience of the inputs and outputs of these generative models are really astounding. On the left you have some of the outputs out of Imagen, a generative text-to-image model made by Google Research. You can ask it to render "a hamster wearing an orange beanie holding a sign that says 'I love JAX'", and it will render a sensible image. Google researchers have also trained a large language model called PaLM now that can explain why jokes are funny. They train these models on really advanced hardware like TPUv4, and over in computer vision researchers are starting to develop some really sophisticated architectures like Vision Transformers.
As a roboticist, I can't help but feel a little envious. I'm still training ResNet18 networks, and that's an architecture that's almost 7 years old. I'm most certainly not training on such large datasets and rarely does robotics work make the flashy headlines.
I know that Moravec's Paradox says that robotics is hard compared to the more cognitive-type tasks. Manipulation is indeed difficult, but intuitively it feels like being able to pick up objects and transport them is … just not as impressive as being able to conjure the fantastical or explain jokes.
First, let me give a definition of what I think generative modeling is. Generative Modeling is not just about rendering pretty pictures or generating large amounts of text. It's a framework with which we can understand all of probabilistic machine learning. There are just two core questions:
- How many bits are you modeling?
- How well can you model them?
In 2012 there was the AlexNet breakthrough - an image-conditioned neural network that predicts one of a thousand classes. log2(1000 classes) is about 10 class bits. So you can think of AlexNet as an image-conditioned generative model over 10 bits of information. If you upgrade the difficulty of the modeling task to MS-CoCo captioning, that's image-conditioned again, but this time you're generating about a tweet's worth of text. That's on the order of 100 bits. Dialogue modeling is similar (O(100) bits), except it's text-conditioned instead of image-conditioned. If you're doing image generation, e.g. text-to-image with DALLE or Imagen, that's on the order of 1000 bits.
Generally, modeling more bits requires more compute to capture those conditional probabilities, and that's why we see models being scaled up. More bits also confers more bits of label supervision and more expressive outputs. As we train larger and larger models, you start to be able to exploit structure in the data so that you can learn much richer structure. This is why generative modeling and self-supervised learning has emerged as a viable way to do deep learning on rich inputs without necessarily requiring copious quantities of human labels.
Rich Sutton's essay The Bitter Lesson provocatively suggests that most of the progress in AI seems to be riding on this rising tide of compute, and very little else. I asked DALLE-2 to draw a depiction of this, where you have this ocean wave of compute that is lifting all the methodss up. You have Vision Algorithms, NLP, and Yann LeCun's "LeCake" all being buoyed up by this trend.

What gives us the most generalization in this regime? You have large over-parameterized models that can handle bigger datasets, and are able to attend to all the features in the prior layers (attention, convolutions, MLPs). Finally, if you have a lot of compute and a stable training objective (Cross Entropy loss), deep learning will almost always work.
I asked DALL-E 2 to draw "a pack mule standing on top of a giant wave", and this is how I think of generative modeling taking advantage of the Bitter Lesson. You have a huge wave of compute, you have a "workhorse" that is a large transformer, or a modern resnet, and at the very top you can choose whatever algorithm you like for modeling: VQVAE, Diffusion, GAN, Autoregressive, et cetera. The algorithmic details matter today but they probably won't in a few years once compute lifts all boats; Scale and good architectures is what enables all that progress in the long term.

By comparison, this is what the state of robotic generalization looks like. Speaking for myself, I'm still training small architectures, I have yet to use a Vision Transformers yet, and here is the roboticist and their safety harness.

I don't meant to sound excessively negative here. I work on robotics full time, and I want more than anyone for the robotics community to leverage a lot more generalization in our work. In some ways this contrast between robotics and generative modeling is not very surprising - if you look at the field of generative modeling, they don't have to work on all the annoying problems that roboticists have to deal with, like setting up the data problem and handling deployment and having the real world inject a lot of noise into your data.
In any case I want to compare generative modeling to robotics in three different dimensions and examine how we can do things better: optimization, evaluation, and expressivity. Maybe if we examine their differences we can figure out some ways to speed up robotics research.
Optimization
Let me first start by explaining a simple generative model, and then cast robotics into the language of generative modeling. Consider a PixelRNN, which is an architecture for generating images.
![]()
You start with a prior for your first pixel's first red channel. Your model tells the canvas (top row) what pixel (3-bit uint8) it wants to paint. Your canvas will be drawn exactly as commanded, so it copies the uint8 value onto the canvas, and then you read the canvas back into your model to predict the next channel - the green channel. You then feed in the R,G canvas values back into the RNN, and so on and so forth, generating RGBRGBRGB…
In practice for image generation you can use diffusion or transformers, but let's assume for simplicity it's a RNN that runs only in the forward direction.
Now let's cast the problem of general control as a PixelRNN. Instead of drawing a picture, you'd like to draw an MDP - a sequence of states, actions, and rewards. You want to draw a beautiful MDP which corresponds to an agent (such as a robot) accomplishing some task. Again, you start with a prior that samples some initial state, which in this case is the RL environment giving you some starting state. This is the first input to your model. Your RNN samples the first "pixel" (A), and again, the canvas draws the A exactly as you asked. But unlike the previous example where the canvas is always handing back to you your previous RNN outputs, now the next two pixels (R, S) are decided by this black box called "the environment", which takes in your action and all the previous states and computes R, S in some arbitrary way.
![]()
You can think of an RL environment as a "painter object" that takes your RNN actions and rather than directly painting what you want onto the canvas, it draws most of the pixels for you, and this can be arbitrarily complex function.
If we contrast this to the previous example of a Pixel-RNN for drawing images, this is a more challenging setting where you're trying to sample the image that you want, but there is a black box that's in getting in the way, deciding what it's going to draw.
Furthermore, there's a classic problem in control where if your environment draws a state that you didn't really expect, then there's a question of how you issue a corrective action so you can return to the image you're trying to draw. Also, unlike image generation, you actually have to generate the image sequentially, without being able to go back and edit pixels. This also presents optimization challenges since you can't do backprop through the black box and have to resort to score function gradient estimation or zeroth-order optimization methods (like evolutionary strategies).
Here's a research idea - if we want to understand how RL methods like PPO generalize, we ought to benchmark them not with control environments, but instead apply them to image generation techniques and compare them to modern generative models. There's some work by Hinton and Nair in 2006 where they model MNIST digit synthesis with a system of springs. DeepMind has revived some of this work on using RL to synthesize images.
Image generation is a nice benchmark for studying optimization and control, because it really emphasizes the need to generalize across hundreds of thousands of different scenarios. You can inject your environment into the painter process by having the sampling of green and blue pixels (reward, next state) be some fixed black-box transition with respect to the previous pixels (state). You can make these dynamics as stateful as you want, giving us a benchmark for studying RL in a "high generalization" setting where we can directly compare them to supervised learning techniques tasked with the same degree of generalization.
Lately there's been some cool work like Decision Transformer and Trajectory Transformer and Multi-Game Decision Transformer showing that upside-down RL techniques do quite well at generalization. One question I'm curious about these days is how upside-down RL compares to online (PPO) or offline RL algorithms (CQL). Evaluation is also conveninent under this domain because you can evaluate density (under an expert fully-observed likelihood model) and see if your given choice of RL algorithm generalizes to a large number of images when measuring the test likelihood.
Evaluation
If you want to measure the success rate of a robot on some task, you might model it as a binomial distribution over the likelihood of success given a random trial, i.e. "how many samples do you need to run to get a reasonable estimate of how good it is"?
The variance of a binomial distribution is \(p(1-p)/N\), where \(p\) is your sample mean (estimated success rate) \(N\) is the number of trials. In the worst case, if you have p=50% (maximal variance), then you need 3000 samples before your standard deviation is less than 1%!
If we look at benchmarks from computer vision, incremental advances of the 0.1-1% range have been an important driver of progress. In ImageNet object recognition, a 10-bit generative modeling problem, progress has been pretty aggressive since 2012 - a 3% error rate reduction for the first three years followed by a 1% reduction every year or so. There's a huge number of people studying how to make this work. Maybe we're saturating on the benchmark a bit in 2022, but in the 2012-2018 regime, there was a lot of solid progress.
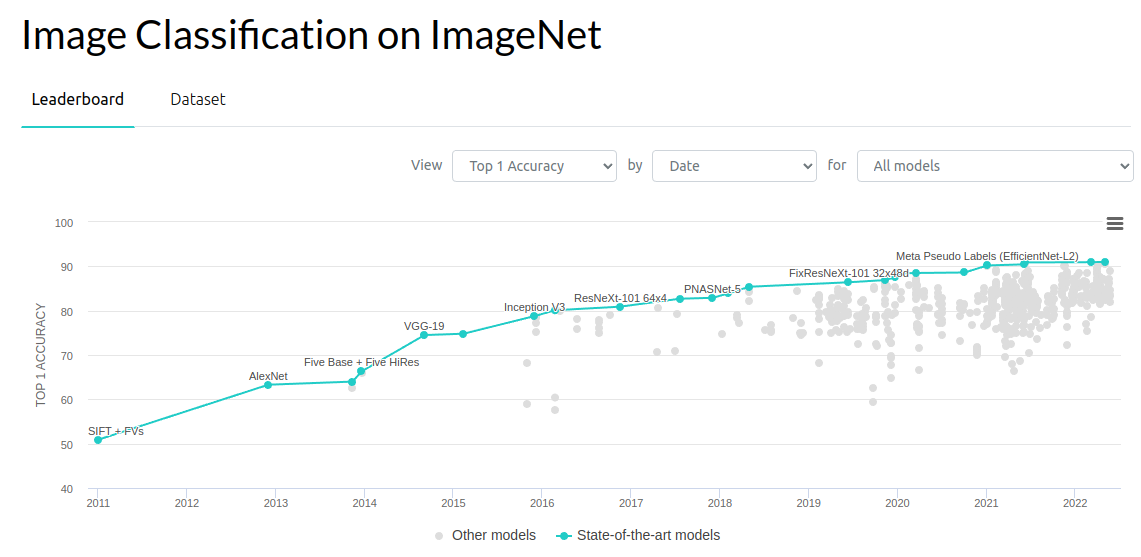
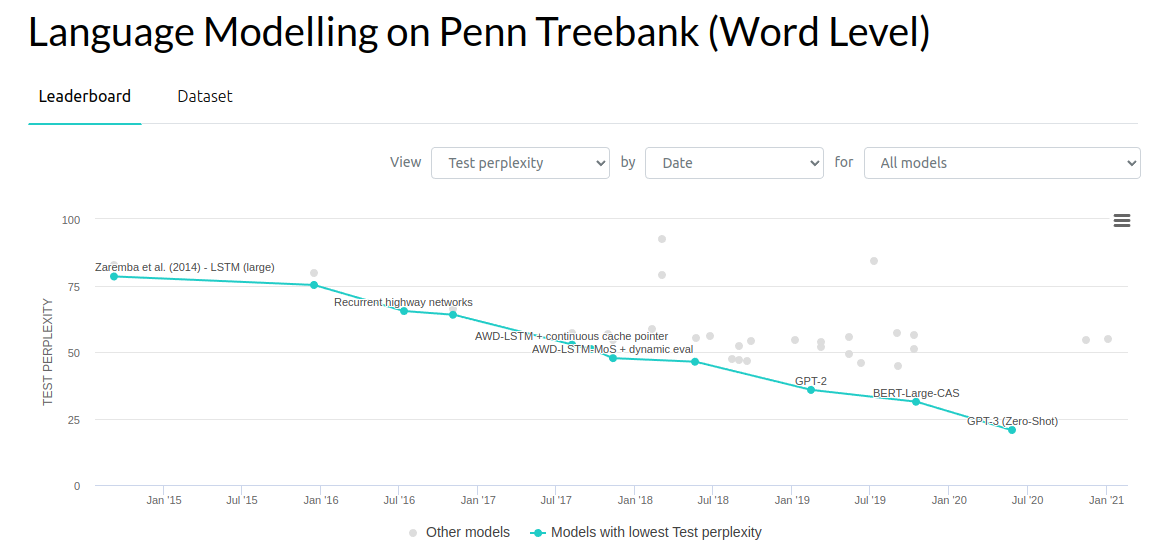
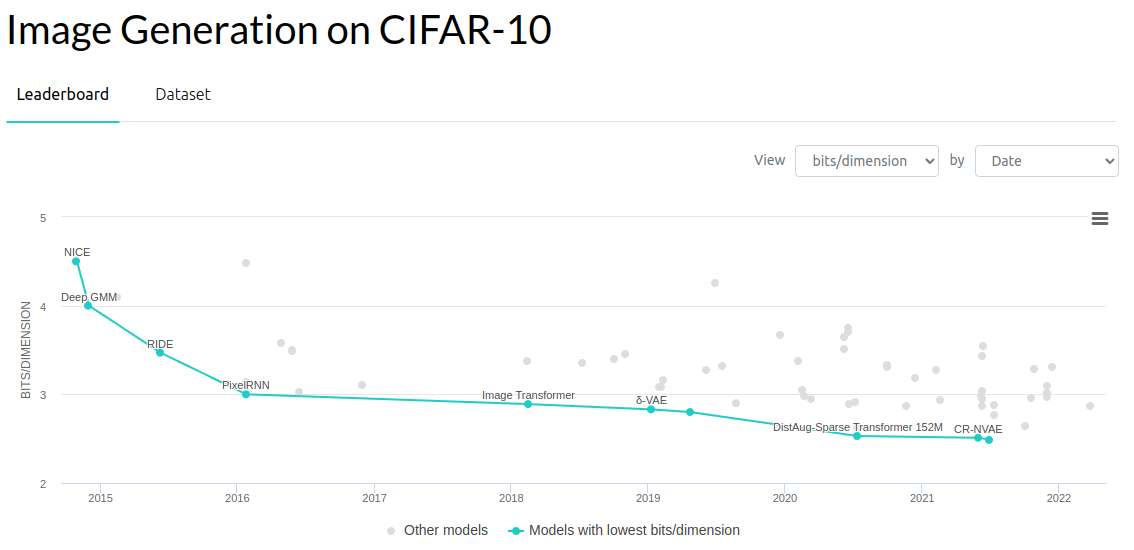
Similarly in other areas of generative modeling, researchers have been pushing down the perplexity of language models and likewise the bits-per-dimension of generative models on images.
Rigorous evaluation across a lot of scenarios takes time. Let's compare some evaluation speeds for these general benchmarks. The 2012 ImageNet object recognition test set has 150,000 images in the test set. It will take about 25 minutes to evaluate every single test example, assuming a per-image inference speed of 10ms and that you are serially evaluating every image one at a time. In practice, the evaluation is much faster because you can mini-batch the evaluation and get SIMD vectorization across the batch, but let's assume we're operating in a robotics-like setting where you have to process images serially because you only have 1 robot.
Because there are so many images, you can get your standard error estimate within 0.1% (assuming a top-1 accuracy of 80% or so). Maybe you don't really need 0.1% resolution to make progress in the field - 1% is probably sufficient.
Moving up the complexity ladder of evaluation, let's consider evaluating neural networks for their end-to-end performance in a simulated task. Habitat-Sim is one of the faster simlators out there, it's been designed to minimize the overhead between the neural net inference and the stepping of the environment. The simulator can step at 10,000 steps per second, but since the forward pass of a neural net is about 10ms, that bottleneck results in a 2 second evaluation per episode (assuming a typical navigation episode is about 200 steps). This is much faster than running a real robot but much slower than evaluating a single computer vision sample.
If you want to evaluate an end-to-end robotic system with a similar level of diversity as what we do with ImageNet, then it'll take up to 4 days to crunch through 150k eval scenarios. It's not exactly apples-to-apples because each episode is really 200 or so inference passes, but we can't treat the images within an episode as independent validation episodes. Absent any other episodic metric, we only know whether the task succeeded or not, so all the inference passes from within an episode can only contribute to a single sample of your binomial estimate. We have to estimate success rate from 150k episodes, not images. Of course, you can try to use fancy off-policy evaluation methods, but these algorithms are not reliable enough yet to "just work" out of the box.
On the next rung of difficulty, we have live evaluations on real robots. When I worked on BC-Z, each episode took about 30 seconds to evaluate in the real world, and we had a team of 8 operators who could run evaluations and measure success rates. each operator could do about 300 episodes a day before they got tired and needed a break. this means that if you have 10 operators, that gets you about 3000 evaluations per day, or roughly 1% standard error on your success rate estimates.
If it takes a whole day to evaluate your model, this creates a ridiculous constraint on your productivity, because you are limited to only trying one idea a day. You can't work on small ideas anymore that incrementally improve performance by 0.1%, or really extreme ideas that have a high chance of not working on the first try, because you simply can't measure those treatment effects anymore. You have to shoot for the moon and go for big jumps in performance. Which sounds nice but is hard to do in practice.
When you factor in the iteration process for doing robotic machine learning, it's very easy to have the number of evaluation trials dwarf those of your training data in the first place! 2 months of nonstop evaluations generates about 60k episodes, which is already larger than most robotic deep learning demonstration datasets. Let me illustrate this point with the broad trends we see in robotic learning becoming more general-purpose over time.

A few years ago researchers were still tackling problems like getting arms to open singular doors. Policies weren't expected to generalize too much, and these papers would evaluate on the order of 10 episodes or so. 10-50 trials is not actually enough for statistical robustness, but it is what it is 👁👄👁. In BC-Z we did on the order of 1000 trials for the final evaluation.
But what happens as we scale further? If we end up using datasets like Ego-4D to train extremely general robotic systems capable of O(100,000) behaviors, how many trials would we need to evaluate such general systems? Once you have something kind of baseline working, how do you re-evaluate a new idea to compare the baseline with? The cost of evaluation here becomes absurd.
Once again - we have enough data; the bottleneck is world evaluation!

How to Speed Up Evaluation?
Here are some ideas on how we can speed up evaluation of general-purpose robotic systems.
One way is to work on generalization and robotics separately. To a large extent, this is what the Deep Learning community does already. Most computer vision and generative modeling researchers don't test their ideas directly on actual robots, but instead hope that once their models acquire powerful generalization capabilities, it will transfer relatively quickly to robots. ResNets, which were developed in the Computer Vision community, have dramatically simplified a lot of robotic visuomotor modeling choices. Imagine if a researcher had to test their ideas on real robots every time they wanted to try a different neural net architecture! Another success story is CLIPort, which decouples the powerful multi-modal generalization capabilities of image-text models from the basic geometric reasoning used for grasp planning.
You can further stratify the tech stack for RL into "simulated toy environments", "simulated robots" and "real robots", in increasing order of evaluation difficulty.
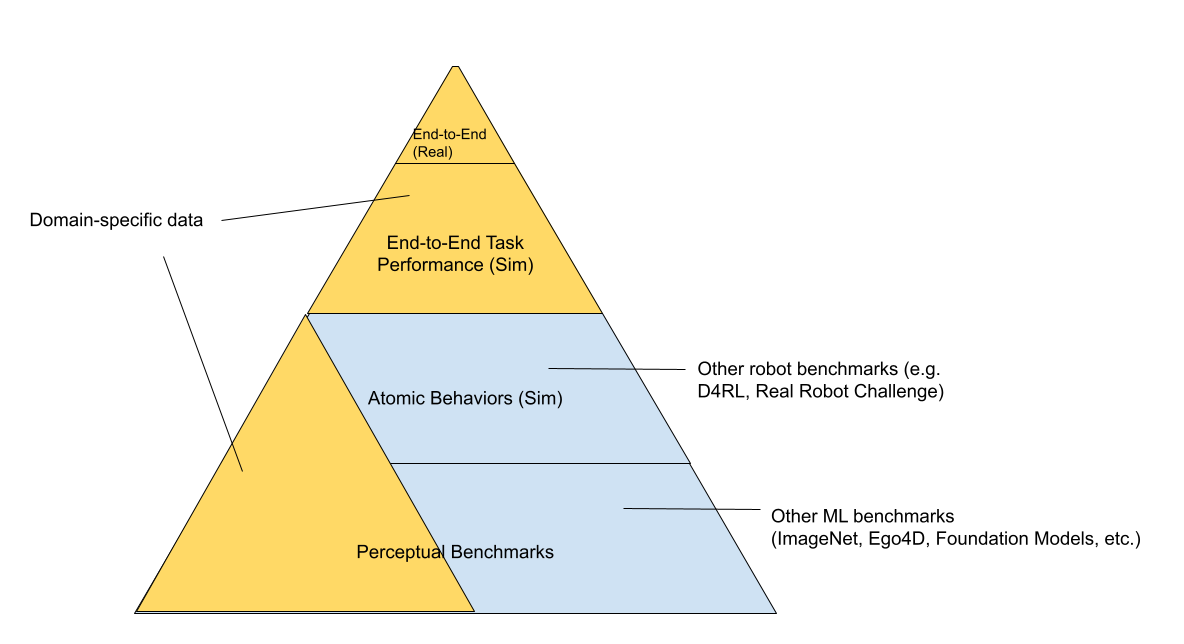
On the bottom layer of the pyramid, you have the general perception benchmarks that are like Kaggle competitions and super easy for the Internet community to iterate on. Moving up the stack, you have a set of "toy control problems" which study the problem in a "bare metal" way, with only the simulator and the neural net running, and all the code related to real world robotics like battery management and real-world resets are non-existent. As you go up the pyramid, it becomes more domain-specific and more relevant to the problem you're trying to solve. For instance, the "simulated robot" and "real robot" stack might be for the same task and re-use the same underlying robot code. Simulated toy environments can be used to study general algorithms, but may have less domain overlap with the end robotic use case. On top of the "evaluation pyramid", you have the actual robotic task you are trying to solve. Iterating on this directly is very slow so you want to spend as little time here as possible. You'd hope that the foundation models you train and evaluate on the lower layers help inform you what ideas work without having to do every single evaluation at the top layer.
Again, the field already operates in this decoupled way. Most people who are interested in contributing to robotics don't necessarily move robots; they might train vision representations and architectures that might eventually be useful for a robot. Of course, the downside to de-coupling is that improvements in perceptual benchmarks do not always map to improvements in robotic capability. For example, if you're improving mAP metric on semantic segmentation or video classification accuracy, or even lossless compression benchmark - which in theory should contribute something eventually - you won't know how improvements in representation objectives actually map to improvements in the downstream task. You have to eventually test on the end-to-end system to see where the real bottlenecks are.
There's a cool paper I like from Google called "Challenging Common Assumptions in Unsupervised Learning of Disentangled Representations", where they demonstrate that many completely unsupervised representation learning methods don't confer significant performance improvements in downstream tasks, unless you are performing evaluation and model selection with the final downstream criteria you care about.
Another way to reduce the cost of evaluation is to make sure your data collection and evaluation processes are one and the same. In BC-Z we had people collecting both autonomous policy evaluation data and expert teleoperation data at the same time. If you're doing shared autonomy, you can use interventions to collect HG-dagger data to gather interventions for the policy, which gives you useful training data. At the same time, the average number of interventions you do per episode tells you roughly how good the policy is. Another thing you can do is look at scalar metrics instead of binomial ones, as those yield more bits of information per episode than a single success/failure bit.
Autonomous data collection with RL learning algorithms is another natural way to merge evaluation and data collection, but it does require you to either use human raters for episodes or to engineer well-designed reward functions. All of these approaches will require a large fleet of robots deployed in real world settings, so this still doesn't get around the pain of iterating in the real world.
An algorithmic approach to evaluating faster is to improve sim-to-real transfer. If you can simulate a lot of robots in parallel, then you're no longer constrained. In work led by Mohi Khansari, Daniel Ho, and Yuqing Du, we developed this technique called "Task Consistency Loss" where we regularize the representations from sim and real to be invariant, so that policies should behave similarly under sim and real. When you transfer a policy evaluated in simulation to real, you want to ensure that the higher performance in sim indeed corresponds to higher performance in real. The less the sim2real gap is, the more you can virtualize eval and trust your simulated experiments.
Expressivity
Let's examine how many bits a modern generative model can output. A 64x64x3 RGB image at 8 bits per channel is 36864 bits. A language model can generate any number of tokens, but if we fix the output window to 2048 tokens, at 17 bits per token that's 36793 bits. So both image and text generative models can synthesize about 37k bits. As your models become super expressive, there is a large qualitative jump in how people perceive these models. Some people are starting to think that Language Models are partially conscious because of how expressive they are.

How expressive are our robotic policies today, by comparison? In BC-Z most of our tasks consisted of about 15-choose-6 objects on the table and the robot had to move one object on top of another or push some object around, for a total of 100 tasks. log2(100 tasks) is about 7 configuration bits, or in other words, "given the state of the world, the robot is able to move the atoms into one of N states, where N can be described in 7 bits". SayCan can do about 550 manipulation tasks with a single neural network, which is pretty impressive by current robotic deep learning standards, but altogether it's just about 10 configuration bits.
It's not a perfect apples-to-apples comparison because the definition of information is different between the two, but it's rather just to provide a rough intuition of what matters when humans size up the relative complexity of one set of tasks vs. another.
One of the challenges here is that our robotic affordances are not good enough. If you look at the Ego4D dataset, a lot of tasks here require bimanual manipulation, but most of our robots today we're still using mobile manipulators with wheeled base, one arm. It's a limited affordance where you can't go everywhere and obviously you only have one arm so that excludes a lot of the interesting tasks.

I think expressivity of our robotic learning algorithms are limited by our hardware. That's one of the reasons I joined Halodi Robotics - I want to work on more expressive robotic affordances. Below we have images of the robot opening doors, packing suitcases, zipping them closed, watering plants, and flipping open bottle caps on a water bottle. As your robotic hardware gets closer to the affordances of an actual human, the number of things you can do in a human-centric world go up exponentially.

The last point I'd like to make is that as our robots become more expressive, we are not only going to need Internet-scale training data, but also Internet-scale evaluation. If you look at progress in LLMs, there are now lots of papers that study prompt-tuning and what existing models can and cannot do. There's a collaborative benchmark called BigBench that compiles a bunch of tasks and asks what we can interrogate from these models. OpenAI evaluates their DALLE-2 GPT-3 models in the wild with Internet users. Their engineering and product teams can learn from users experimenting with their AI systems in the wild, as it's too hard for any one researcher to grasp even the input surface area of the models.
My question for the audience is, what is the robotics equivalent of a GPT-3 or DALLE-2 API, in which the broader Internet community can interrogate a robotic policy and understand what it can do?
To conclude, here's a table that summarizes the comparison between optimization, evaluation, and expressivity:
| Generative Modeling | Robotics | |
| Optimization and Generalization: can you compress the test set efficiently? | Model has complete control over which pixels it paints | Model samples an action and a stateful black box paints the next two tokens |
| Evaluation: how quickly can you iterate? | O(25min) to get binomial success rate std < 0.1% | O(months) to get success rate std < 1% |
| Expressivity: How rich are your outputs, in bits? | O(1000) bits make good use of scale and higher-capacity networks | Task configuration space about 10 bits, dramatically limited by robot morphology |
Q/A
What do you think about model-based methods?
Generative models used for visual model-predictive control are nice because they directly reuse a lot of the latest advances from generative modeling of images and video. However, the challenge remains that if you're not evaluating on a robot, it's still hard to know how reduction in bits-per-dim (or ELBO likelihood) for your modeling task translates to actual performance. While model-based learning is super practical for optimizing in a generalization-friendly way, you still need to find a way to connect it to your evaluation.
If model-based learning is practical, why haven't you applied it to BC-Z data?
When setting up a robotic learning codebase, you want to de-risk the infrastructure and make sure the basics like logging are implemented correctly. Often it's a good idea to start with a simple algorithm, even if it's a naive baseline. Imitation learning was the simple algorithm we started with, but obviously once that works then it makes sense to branch out to more complex things like model-based RL.
Is it possible to deploy black-box learned systems (e.g. end-to-end neural network control) in real-world applications, given that they don't have safety guarantees?
This is an open question for the ML field at large, as to what responsible deployment of black box systems should look like. My personal take is that trust comes out of performance. If it performs really well, people will trust it over time. For more short-term pragmatic stuff, what helps a lot is to have shared autonomy and anomaly detection systems that help people catch errors and let people take over. Just as it's hard to define what "out of distribution" means, it's hard to define what "formal safety guarantees" means in unstructured robotic environments. All these are just ill-posed semantics and what we really want is reliability and some degree of internal belief that we know what's going on inside our automated systems.
Do you have a notion of what proxy tasks make sense for robotics?
At the very top of the evaluation pyramid, you have the question "does the robot do the task successfully?" and lower down the evaluation pyramid you have many proxy metrics that you would hope inform you about the performance of the system. One analogy you can draw from the language modeling community is that bits-per-dim is your proxy metric, while a Turing Test is your end-to-end metric. You don't necessarily know how well the Turing Test is going to go, given a reduction in perplexity, but you know that because language models are lossless compressors, that as you approach the limit of human-level compression, it will solve the harder task. So we should be drawing plots of how the end-to-end metric you care about scales with each proxy metric. I suspect a lot of surrogate metrics (e.g. object detection mAP) will probably plateau quickly.
As to a specific proxy metric for robotics, I think simulated task success, and hand-curated "evaluation scenarios" that test for robust policy behavior in critical states are a reasonable start.