Ultra Instinct
There is a blue ocean of opportunity for AI systems that observe and act at a higher frequency than what most chatbots are capable of today.
Visible light occupies a small sliver of the electromagnetic spectrum, which spans radio waves, microwaves, infrared, visible light, ultraviolet, X-rays, and gamma rays.
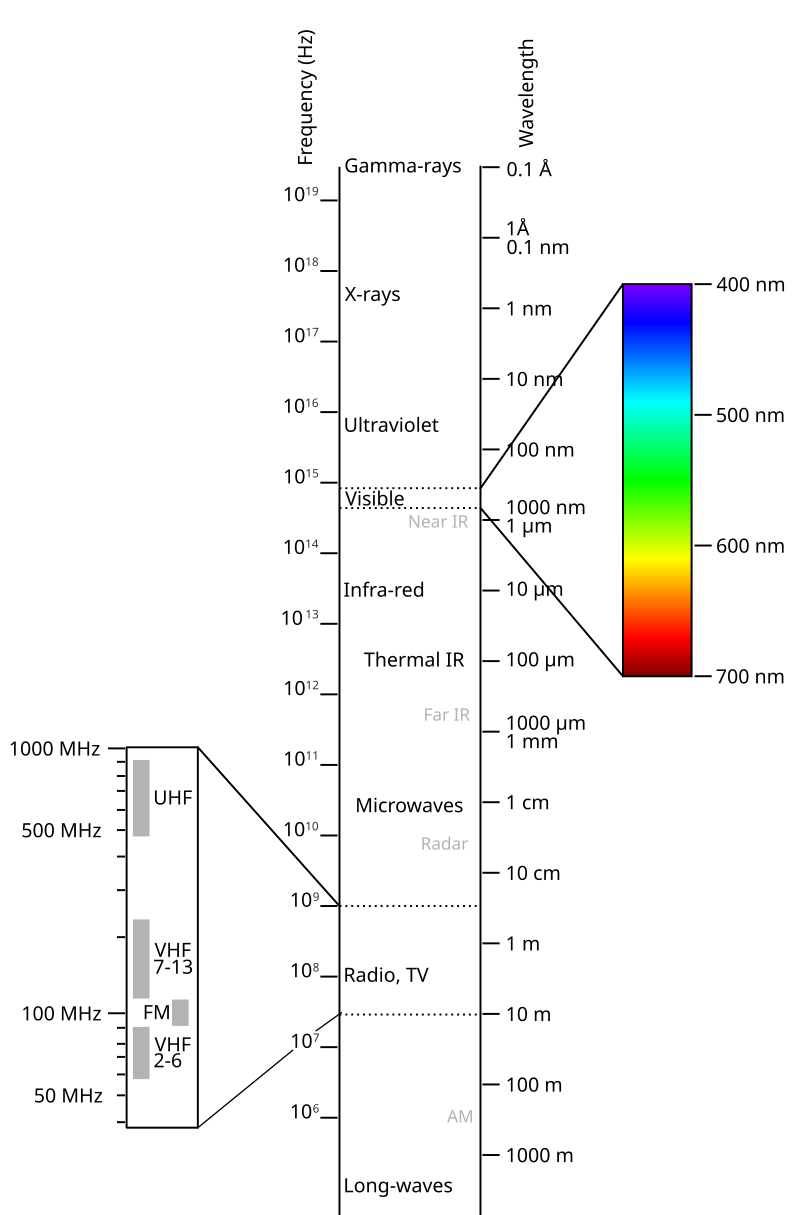
Though invisible to the human eye, these other bands are very real and very useful. Humans use all wavelengths in everyday imaging and communication technologies. Birds and insects can see infrared and ultraviolet radiation, and cat olfactory bulbs can even sense X-rays.
An analogous "frequency spectrum" can be defined for intelligent decision making.
-
Some decision loops happen slowly – what projects should I pursue at work?
-
Other decisions happen more quickly – what should I have for lunch?
-
Others more quickly still – oh shit, I need to swerve my car or I am going to get into an accident!
Like the visible part of the EM spectra, there are decisions that happen at such slow speeds that they are scarcely recognizable as "intelligent behavior".
Balsa and Cecropia trees take the following developmental strategy: Grow shallow roots and a hollow trunk, dedicate all resources to shooting vertically up as fast as possible. Once it is the tallest tree, grow leaves laterally to create a canopy that shades surrounding plants, suppressing their growth.
For a plant, the line between body development and decision making are blurred together; the action space of a plant is to grow in a particular direction. This may not seem like what we typically associate with intelligence, but what is development if not a slow reaction to the environment? Plants behavior seems a lot more coherent when watched in a sped-up timelapse.
On the opposite end of the intelligence frequency spectrum, you have decisions being made so fast that humans scarcely notice them. This includes the delicate force control loop that your fingers exert when turning the page of a book, the flapping of a hummingbird wing, the saccade reflexes of human vision, the expression of proteins at the cellular level. They happen faster than our conscious processing, so we have a hard time sensing their intelligent purpose. Everyday dextrous human manipulation appears more smart when slowed down.
For Homo sapiens, our greatest opportunities and threats in our environment come from other humans, so we are highly attuned to recognize intelligence in specific frequencies, much like how we only see specific frequencies of EM radiation and how we pay a lot more attention to human faces than other objects.
1Hz Intelligence
AI chat assistants occupy a very narrow band of the intelligence frequency spectrum. They are largely turn-based: you upload some text and images, and 1-2 seconds later, you get back some text and images. Everybody is building the same thing.
The time-to-first token (TTFT) of a modern LLM like is approximately 500ms, and around 200-400ms for smaller models like Llama-3-70b.
Due to this reaction time, modern LLMs can be thought of as 1-2hz intelligence. It is almost – but not quite – human speed. Natural in-person human conversation switches faster, about 5-10hz. The relatively slow reaction speed of LLMs compared to humans means that the UX for all AI assistants today are still stuck in a turn-based, non-realtime context.
ChatGPT Advanced Voice Mode, Gemini Live and Grok Companion are examples of multi-modal models that reduce latency of speech-to-speech generation, but due to the size of the model involved, have a latency of about 500ms-1000ms to respond after a user has finished speaking. It is still quite frustrating to attempt to interact with these "voice" models in a truly seamless way - it feels like phoning a friend with laggy cellular reception: you have to take turns, wait for half a second before jumping in to say something.
AI assistants that don’t perceive and react at 1x human speed are incompatible with interfacing with humans in the most natural way possible. The AI cannot "live" in a human world like Samantha from Her; instead, humans must "slow down" for the LLM by typing, waiting for their turn to talk, uploading images one at a time by clicking buttons on their phone.
Assisting at 1X Speed
Human kinematic decision making – where should I visually attend to, and where should my hands and feet go – runs at about 10hz. If we want assistants with good nonverbal communication abilities that interact with people in the human world (e.g. a humanoid robot like NEO), they have to be communicating with humans and perceiving human responses at this frequency.
An intelligence with a 100ms reaction time that "lives" in the real world will be a very qualitatively different user experience. It can do active listening and mirror your gestures while you’re talking to convey comprehension, it can notice you approaching a door and open it for you, and it has the awareness to know that you want to interrupt its speech based on visual cues. This feels much more natural and aware of its surroundings, like talking to a friend.
What will it take to create AI assistants with much faster multi-modal reaction times, that have the ultra instinct?
- You need both fast reaction times (TTFT) and long context. We need to re-think the fast and slow parts of generalist models to satisfy these types of inference constraints. If you’re in the middle of an emotionally charged conversation, you want to pay attention to high-frequency human micro-expressions, and yet accumulate a long duration of conversational context, and also think really hard about what to say. There are models that are good at each of these but not all of them.
- We’ll need better video encoders. The VJEPA-2 paper showed that by fine-tuning a LLM decoder on top of the pretrained video encoder, they were able to achieve SOTA VideoQA results. Despite this relatively weak multi-modal fusion technique, there was still a huge performance boost to be gained simply by improving the video encoder only. I think that there is a ton of low-hanging fruit in pretraining better single-modality encoders, though it remains non-obvious if a contrastive approach or approximate-likelihood world model leads to better representations.
- Video is not enough: Humans are estimated to receive 10^9 bits per second across their sensors, and yet we consciously only perceive 10 bits/s. That is just one token per second (vocab size of 1024), but we don’t have tokenizers that can compress 10^9 bits of multimodal sensor data in real time. A model that can pay attention to body language needs to handle large amounts of multi-modal and high-frequency temporal context compared to what most models can do today: the flash of surprise across someone’s face when you say something wrong, the prosody change when someone is speaking, the beckoning hand gestures of a user as it asks the robot to follow it.
How we reconcile these three problems at the same time will be tricky, and is something no AI lab has today. There is likely a lot of room to improve on just better video & audio encoder pre-training, but for AI assistants that operate at 1X speed, we have to design architectures that support incredibly low-latency inference. I'm looking to hire for people who can solve this!.
Once we broaden our understanding of AI to occupy wider bands of the intelligence frequency spectrum (both faster and slower), I think we will find that there are still plenty of intelligence tokens out there on the Internet. It has been merely hard for us to perceive through our anthropomorphic biases. If you slow down fast videos, there is plenty of intelligence in between the frames. If you speed up videos of slow processes (like plants growing), there are more intelligence tokens to be found there as well.
Grok Think, Grok Car, Grok Bot, Grok Waifu
The year is 2027. Your day begins with you opening the X The Everything App to hail a Tesla Cybercab to go work. You have the standard $200/mo subscription on X, not the $2000/mo tier, so for your 30m car ride you are forced to talk to Grok, which sort of acts as your personal Jordan Peterson, unrivaled in its ability to Gish Gallop and draw statistics from the entirety of human knowledge to support whatever it wants to persuade you of.
During your car ride, Grok Peterson attempts to convince you that Trump should be impeached. The driver-facing camera in the car can read your facial expressions and body language at 10hz so the model understands the difference between you actually comprehending its arguments, versus you just politely nodding and zoning out. Grok Peterson adjusts accordingly in real-time.
At work, you use Grok Think to do 90% of your job. You’re a bit concerned about the folds in your brain having gotten smoother over the last few months, so you turn to Grok Truth for some medical advice. It warns you about the dangers of gender-affirming surgery and supporting social justice movements, and recommends Ozempic to curb your doomscrolling.
After a long day at work, you go home to Grok Waifu running on your Tesla Optimus Bot, which is the closest thing you have to a friend.
The future may be closer than you think. We’re starting to see Grok being integrated into Tesla cars and Tesla robots and tackle these higher-frequency, multi-modal decisions in the real world. Anything that Neuralink interfaces with must obviously run at real-time human speeds. It’s really impressive how all the Elon Musk companies are integrating their technology.
On the other hand, this is some dystopian Lex Luthor type shit! I would prefer to live in a world where not all of the cool sci-fi technology is controlled by Elon Musk. It is only a matter of time before other AGI labs wake up and understand what is at stake here beyond the current paradigm of 1Hz chatbot assistants. I hope that 1X plays a part in providing consumer choice in "ultra instinct" AGI systems.
Most AI labs today compete on the same benchmarks on the same part of the frequency spectrum, but there are very few benchmarks catered towards multi-modal decisions with specific reaction times. As simulators and closed-loop world models improve, I think we will start to see more competition on these bands.
Perhaps by late 2027, anything that cannot act smartly at a broad spectrum of decision frequencies, from 0.1hz to 50hz, both embodied and digital, will seem like an "incomplete AGI". Your grandma’s favorite AGI will not be ChatGPT or Claude, but probably a robot, and hopefully one made by 1X!.